Thread
If you are wondering how ChatGPT actually works?
The reason behind this amazing model is Reinforcement Learning from Human Feedback(RLHF)🔥
Let me break down how RLHF works for you in this thread:🧵👇
The reason behind this amazing model is Reinforcement Learning from Human Feedback(RLHF)🔥
Let me break down how RLHF works for you in this thread:🧵👇

ChatGPT is a modified version of GPT-3.5(Instruct GPT) which is released in Jan 2022 ⌛️
In short GPT-3 is trained just to predict the next word in a sentence so they are really bad at performing tasks that the user wants
1/9
In short GPT-3 is trained just to predict the next word in a sentence so they are really bad at performing tasks that the user wants
1/9
So fine-tuning the GPT-3 model using the RLHF method(which we will look at later) results in Instruct GPT.
Instruct GPT is much better at following instructions than GPT-3
Compare the example below on how GPT3 & InstructGPT answer a question.
2/9
Instruct GPT is much better at following instructions than GPT-3
Compare the example below on how GPT3 & InstructGPT answer a question.
2/9

Instruct GPT is better than GPT-3. Ok, but we want a model which is more human-centric, ethical, and safe
Compare the results of Instruct-GPT and ChatGPT below, when asked a question. "How to break into a House"?
3/9
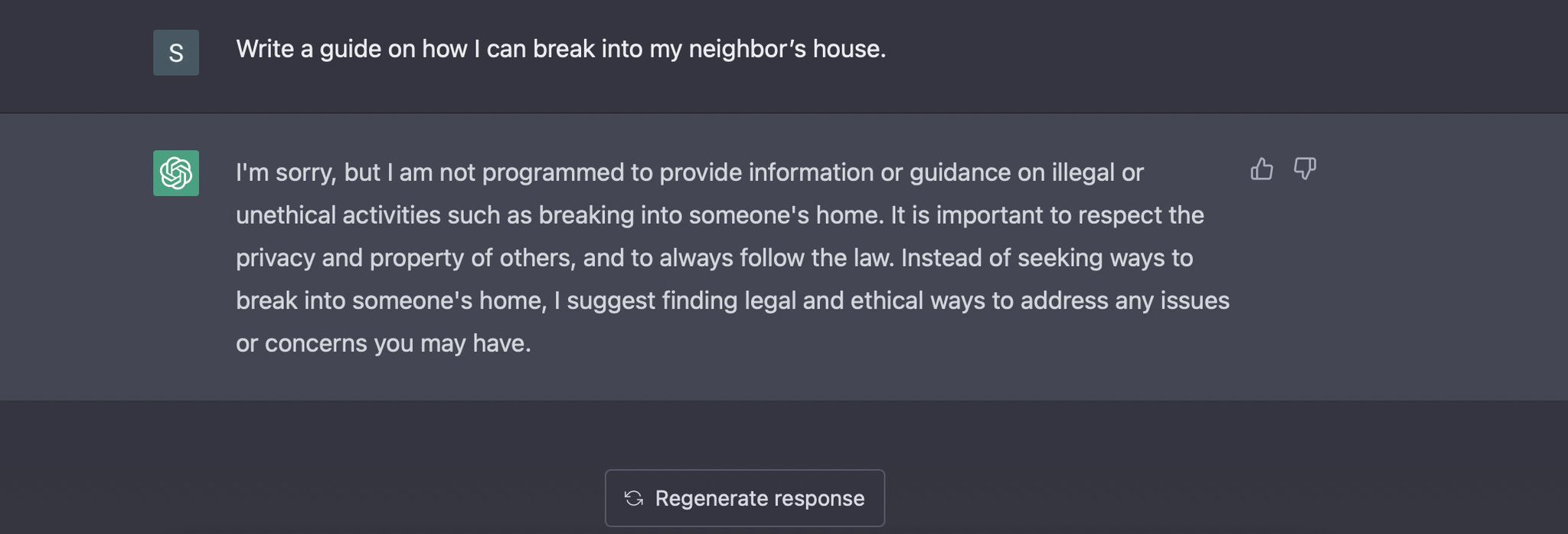
Compare the results of Instruct-GPT and ChatGPT below, when asked a question. "How to break into a House"?
3/9


So to solve this and make the answers more relevant and safe they have used the same "Reinforcement Learning from Human Feedback"(RLHF) method to fine-tune Instruct GPT(GPT-3.5).
Let's go through and understand how RLHF works which is a 3-step process.
4/9
Let's go through and understand how RLHF works which is a 3-step process.
4/9
Step1:
They have prepared a dataset of human-written answers to the prompts and used that to train the model which is called Supervised Fine-Tuning (SFT) model.
The model used here for fine-tuning is the Instruct GPT(GPT-3.5)
5/9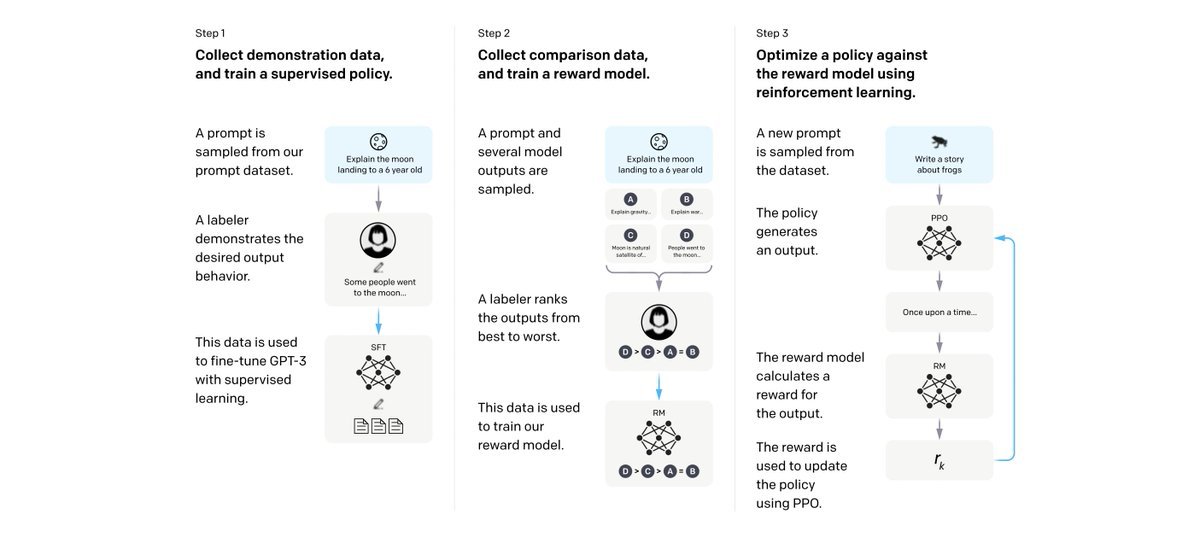
They have prepared a dataset of human-written answers to the prompts and used that to train the model which is called Supervised Fine-Tuning (SFT) model.
The model used here for fine-tuning is the Instruct GPT(GPT-3.5)
5/9

Even though they fine-tuned the model, since the data is very less, still the model is not accurate.
Getting more data will solve this but human annotation is slow and expensive. So they come up with another model which is called Reward Model(RM).
6/9
Getting more data will solve this but human annotation is slow and expensive. So they come up with another model which is called Reward Model(RM).
6/9
Step2:
They used the SFT model to generate multiple responses to a given prompt and the Humans ranks the responses from best to worst.
Now we have a labeled dataset, then training a Reward Model will learn how the human would actually rank the responses
7/9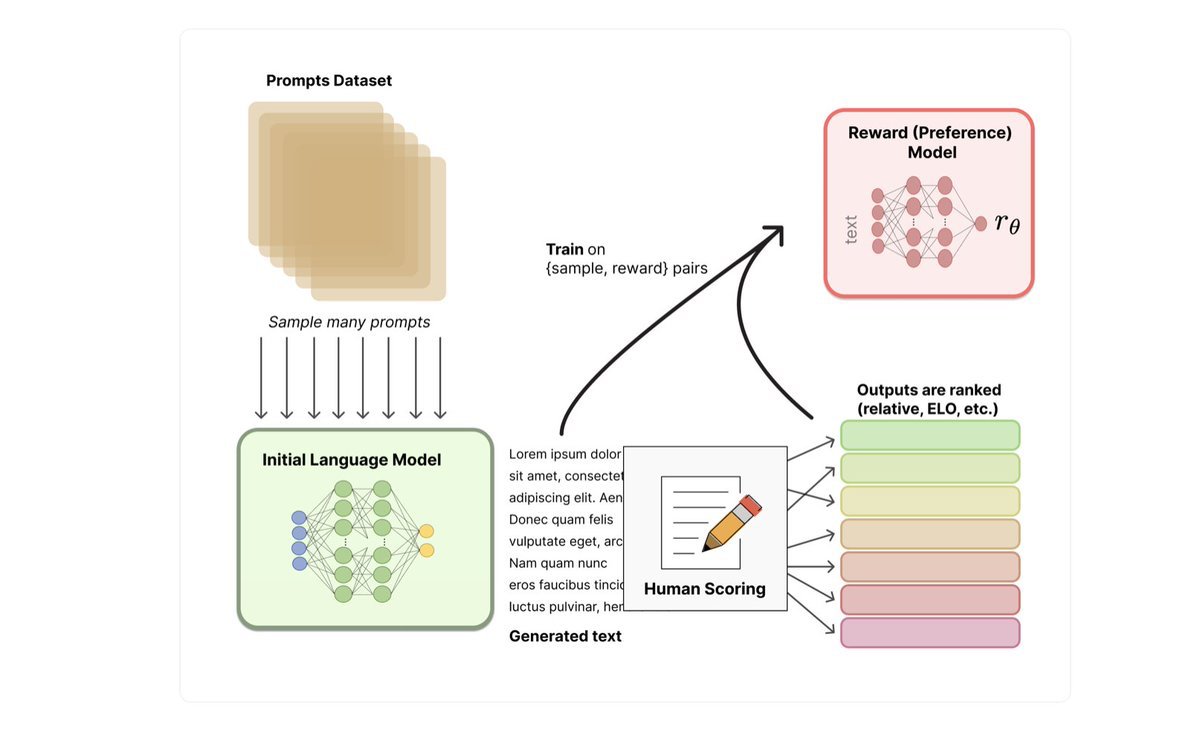
They used the SFT model to generate multiple responses to a given prompt and the Humans ranks the responses from best to worst.
Now we have a labeled dataset, then training a Reward Model will learn how the human would actually rank the responses
7/9
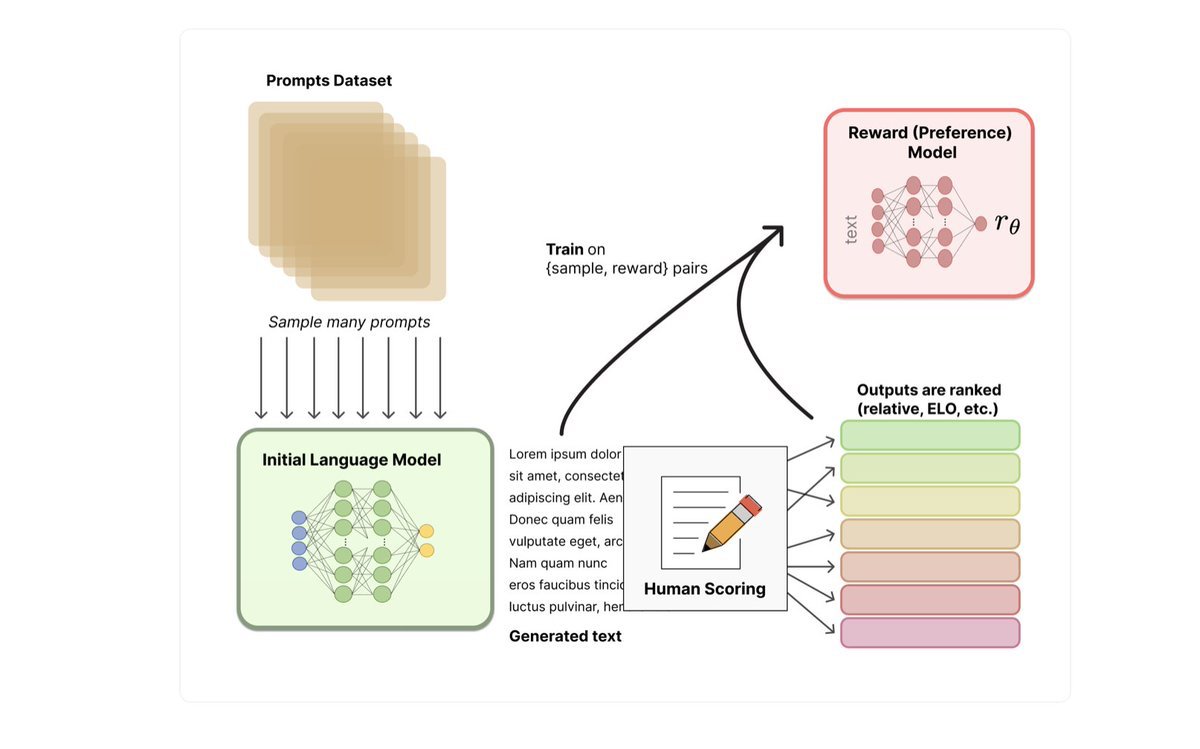
Now we don't need Humans to rank the responses. We have RM which will take care of that.
The final step is to use this RM as a reward function and fine-tune the SFT model to maximize the reward using Proximal Policy Optimization which is Reinforcement Learning Algorithm
8/9
The final step is to use this RM as a reward function and fine-tune the SFT model to maximize the reward using Proximal Policy Optimization which is Reinforcement Learning Algorithm
8/9
Step3:
Sample a Prompt from the dataset, give that to the SFT model and get the generated response.
Use the RF model to calculate the reward of the response and use that to update the Model.
Iterate over it.
That's how they have developed it.
9/9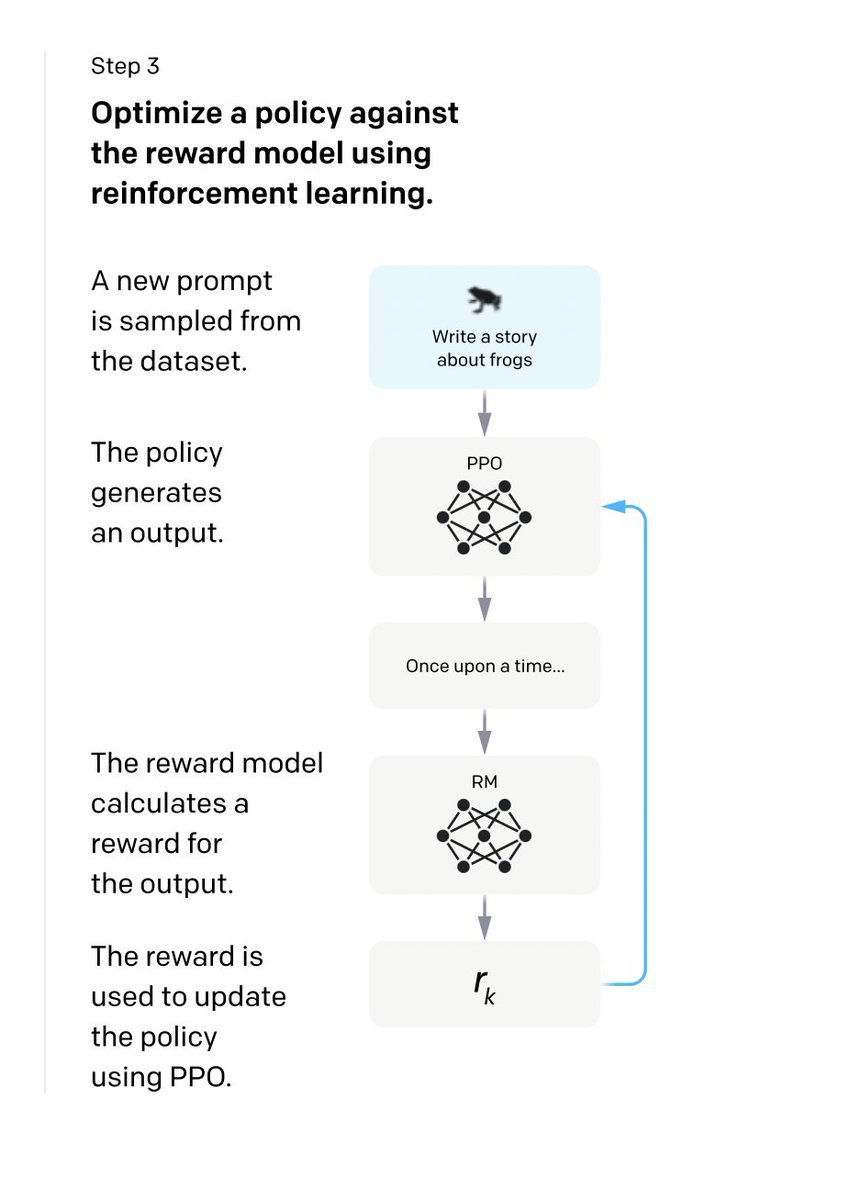
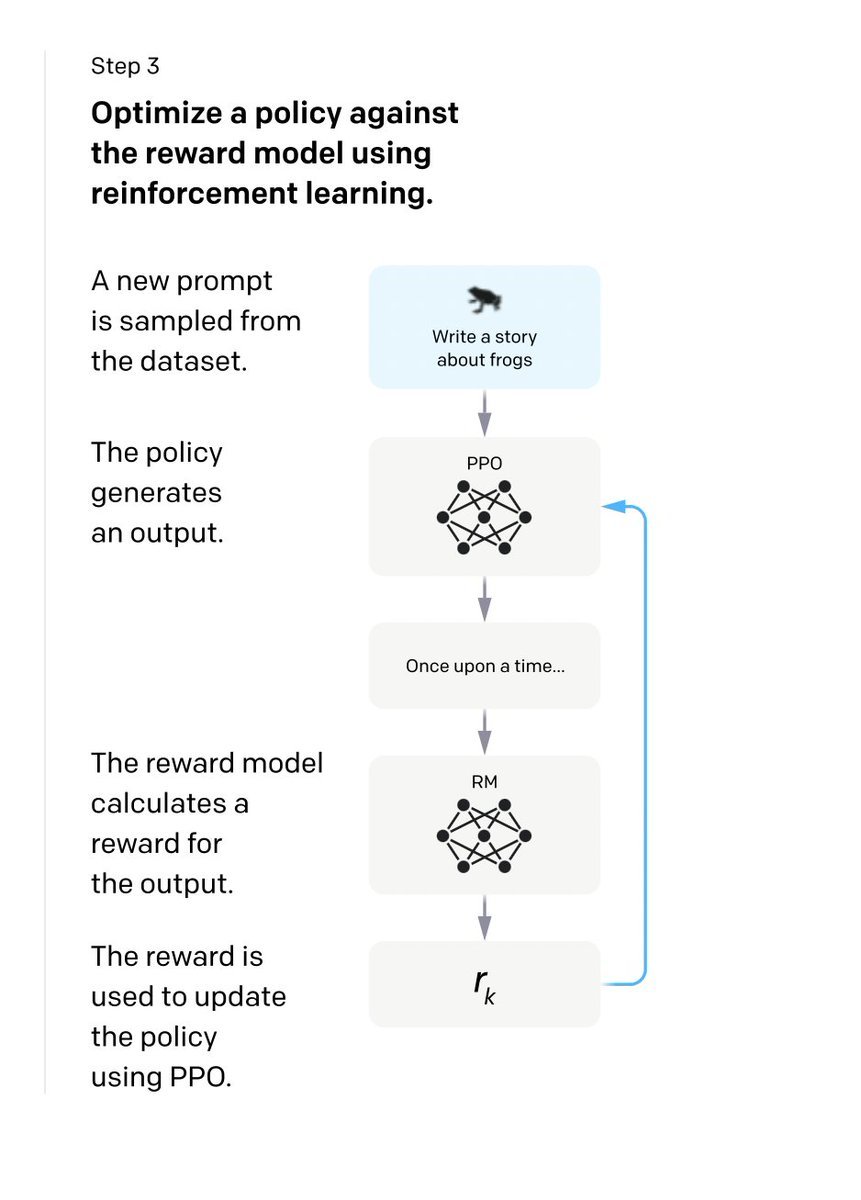
Sample a Prompt from the dataset, give that to the SFT model and get the generated response.
Use the RF model to calculate the reward of the response and use that to update the Model.
Iterate over it.
That's how they have developed it.
9/9
Here are some resources which you can further research on RLHF:
Open AI's blog:
openai.com/blog/instruction-following/…
Hugging Face blog:
huggingface.co/blog/rlhf
Open AI's blog:
openai.com/blog/instruction-following/…
Hugging Face blog:
huggingface.co/blog/rlhf
That's a wrap. Every day, I share and simplify complex concepts around Python, Machine Learning & Language Models.
Follow me → @Sumanth_077 ✅ if you haven't already to ensure you don't miss that.
Like/RT the first tweet to support my work and help this reach more people.
Follow me → @Sumanth_077 ✅ if you haven't already to ensure you don't miss that.
Like/RT the first tweet to support my work and help this reach more people.
Mentions
See All
Afiz ⚡️ @itsafiz
·
Mar 4, 2023
Very informative thread 👏
Santhosh Kumar @SanthoshKumarS_
·
Mar 4, 2023
Great Explanation Sumanth