Thread
Here are a few examples from our work in robotics that leverage bitter lesson 2.0
This is something that I believe we'll see a lot more of (including our own work in 2023)🧵
This is something that I believe we'll see a lot more of (including our own work in 2023)🧵
In SayCan, we showed how we can connect robot learning pipelines to large language models, bringing a lot of common sense knowledge to robotics.
The hope was that as the LLMs become better (which they seem to be consistently doing), it will have a positive effect on robotics.
The hope was that as the LLMs become better (which they seem to be consistently doing), it will have a positive effect on robotics.
In our updated paper: PaLM-SayCan, we indeed observed bitter lesson 2.0 in action - just by changing the LLM to a more performant PaLM we got:
• better performance
• chain-of-thought prompting
• handling of queries in other languages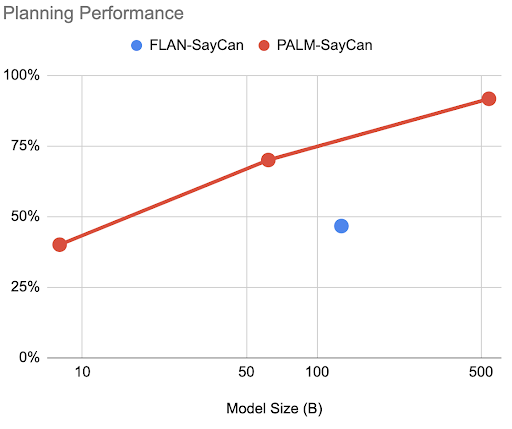
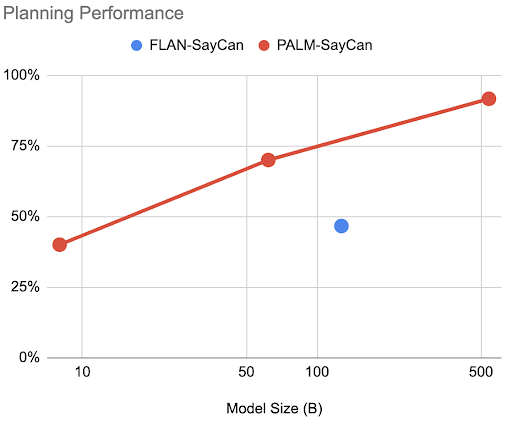
• better performance
• chain-of-thought prompting
• handling of queries in other languages
2nd example is Inner Monologue (innermonologue.github.io/) led by @xiao_ted, @xf1280 and @wenlong_huang, where we bring in VLMs to provide feedback about the scene, task success etc.
All these different models talk to each other in natural language so that LLM can understand.
All these different models talk to each other in natural language so that LLM can understand.
In this case, VLMs bring a lot of non-robotic data into our system allowing us to get better planning feedback mechanisms. With better VLMs, our system can continue to get better without any new robotic data - bitter lesson 2.0
Another example is code-as-policies.github.io/ (led by @jackyliang42 and @andyzengtweets) where we use LLMs to generate code to directly control the robot.
The results here are pretty mind-blowing
The results here are pretty mind-blowing
My favorite quote from @andyzengtweets on this work:
"LLMs read your favorite robotics textbooks too"
This really changed my thinking on what LLMs can do for robotics and what LLMs actually are. It's not just about allowing us to communicate with robots in natural language.
"LLMs read your favorite robotics textbooks too"
This really changed my thinking on what LLMs can do for robotics and what LLMs actually are. It's not just about allowing us to communicate with robots in natural language.
As in the previous cases, as the LLMs get better, the robotic *policies* now will also get better.
Btw, you can play with it yourself @huggingface
Btw, you can play with it yourself @huggingface
Another example: DIAL (work led by @xiao_ted and
@SirrahChan), where we show that VLMs can significantly expand language labels without collecting any additional robot data.
DIAL brings new language concepts into robotics by using foundation models. Yup, bitter lesson 2.0.
@SirrahChan), where we show that VLMs can significantly expand language labels without collecting any additional robot data.
DIAL brings new language concepts into robotics by using foundation models. Yup, bitter lesson 2.0.
Another example is NLMap (nlmap-saycan.github.io/) by @BoyuanChen0 and @xf1280 where VLMs can be used to query objects in the scene and allow for open-vocabulary queries in SayCan.
Better VLMs -> better open-vocab accuracy
Better VLMs -> better open-vocab accuracy
The last robotic example from our own work is RT-1, which doesn't encompass the bitter lesson 2.0 principle as much as the other examples but it shows that the general recipe that worked in other fields (big transformer trained with supervised learning) works in robotics.
That's all in 2022. I'm optimistic that by riding the wave of progress in other fields and leveraging data in disguise from foundation models, we can make significant progress in robotics.
Stay tuned for more progress on this!
Stay tuned for more progress on this!
