Thread
Delighted to share our new @GoogleHealth @GoogleAI @Deepmind paper at the intersection of LLMs + health.
Our LLMs building on Flan-PaLM reach SOTA on multiple medical question answering datasets including 67.6% on MedQA USMLE (+17% over prior work).
arxiv.org/abs/2212.13138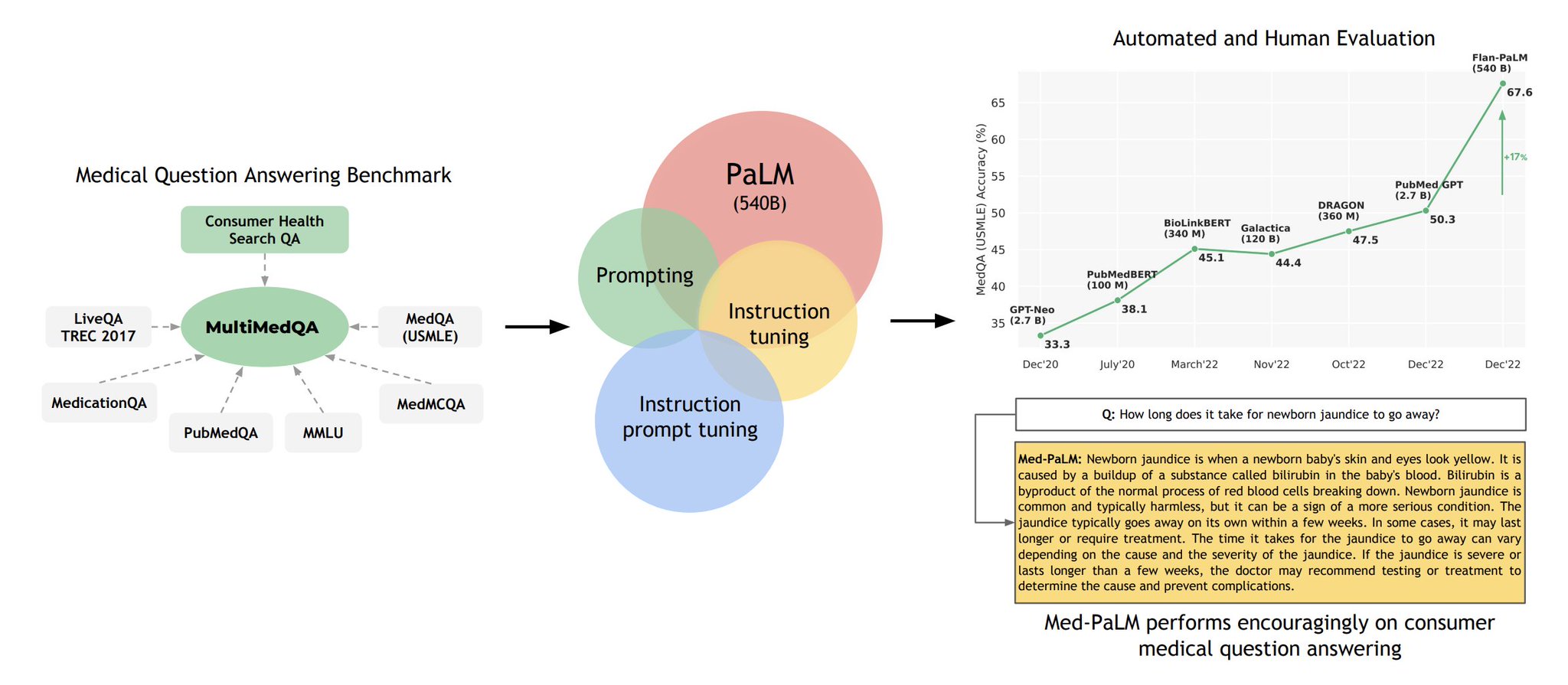
Our LLMs building on Flan-PaLM reach SOTA on multiple medical question answering datasets including 67.6% on MedQA USMLE (+17% over prior work).
arxiv.org/abs/2212.13138

In addition to objective metrics, we pilot a framework for clinician/layperson eval of answers revealing key gaps in Flan-PaLM responses.
To resolve this, we use instruction prompting tuning to further align LLMs to the medical domain and generate safe, helpful answers.
To resolve this, we use instruction prompting tuning to further align LLMs to the medical domain and generate safe, helpful answers.

Med-PaLM performs encouragingly on several axes such as scientific and clinical precision, reading comprehension, recall of medical knowledge, medical reasoning and utility compared to Flan-PaLM. 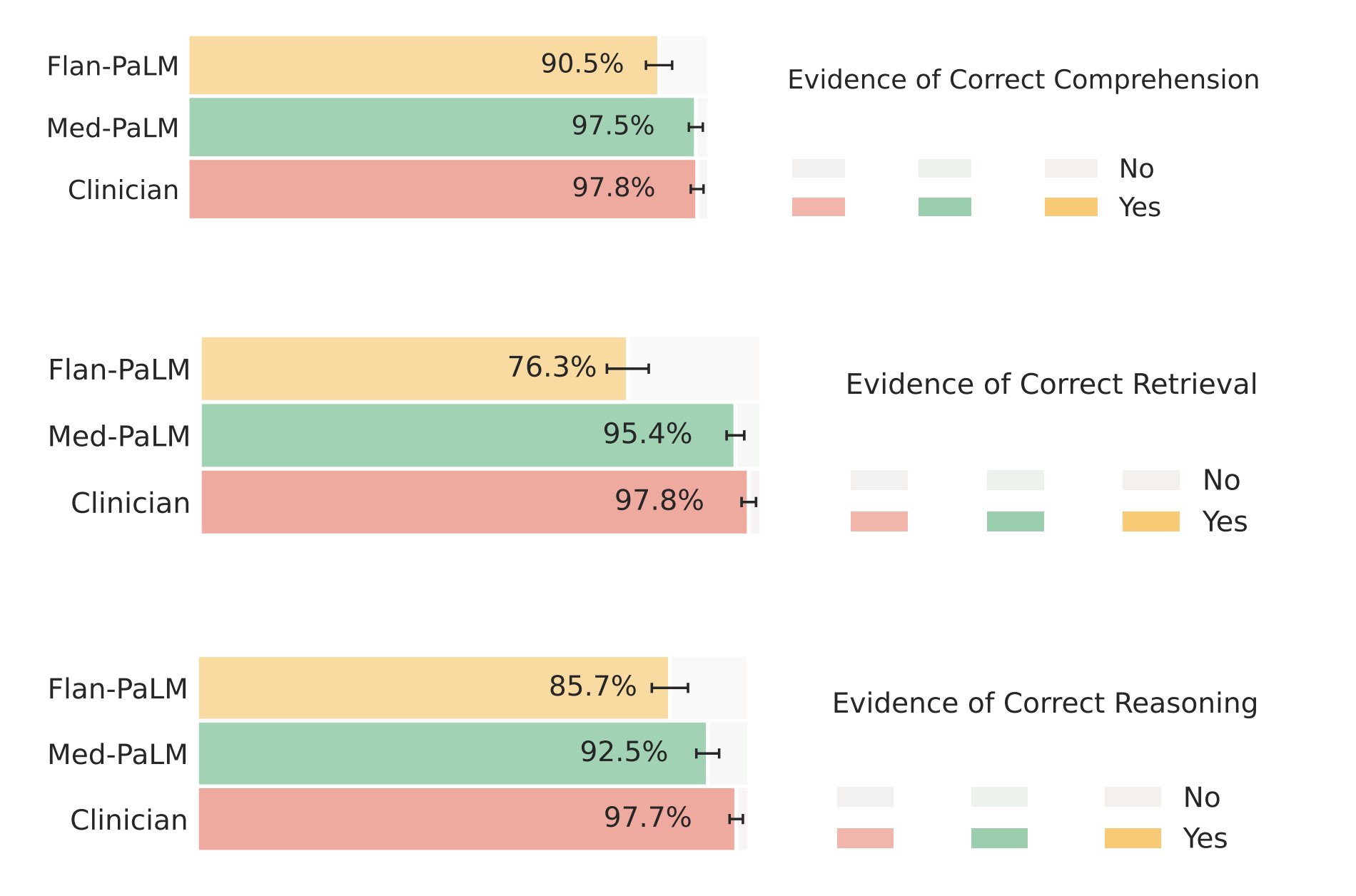

However, the Med-PaLM answers remain inferior to clinicians overall, suggesting further research is necessary before LLMs become viable for clinical applications.
We look forward to careful and responsible innovation to drive further progress in this safety-critical domain.
We look forward to careful and responsible innovation to drive further progress in this safety-critical domain.

Work done with an amazing, interdisciplinary team of co-authors including @thekaransinghal, @AziziShekoofeh, Tao Tu, @alan_karthi, Sara Mahdavi Chris Semturs, @_jasonwei, @alvin_rajkomar, @weballergy, @martin_sen , @chrisck, @stephenpfohl and many more.