Thread
"What Makes Convolutional Models Great on Long Sequence Modeling?"
CNNs—not transformers—now dominate the hardest sequence modeling benchmark.
Here's how this happened: [1/14]
CNNs—not transformers—now dominate the hardest sequence modeling benchmark.
Here's how this happened: [1/14]

First, let's be precise: by "the hardest sequence modeling benchmark," I mean the Long Range Arena (arxiv.org/abs/2011.04006). This consists of tasks like Pathfinder (shown above) that are designed to require modeling of long-range dependencies. [2/14]
For a while, no one did well on the Long Range Arena. In particular, Path-X (a more extreme version of the above Pathfinder task) seemed impossible. [3/14] 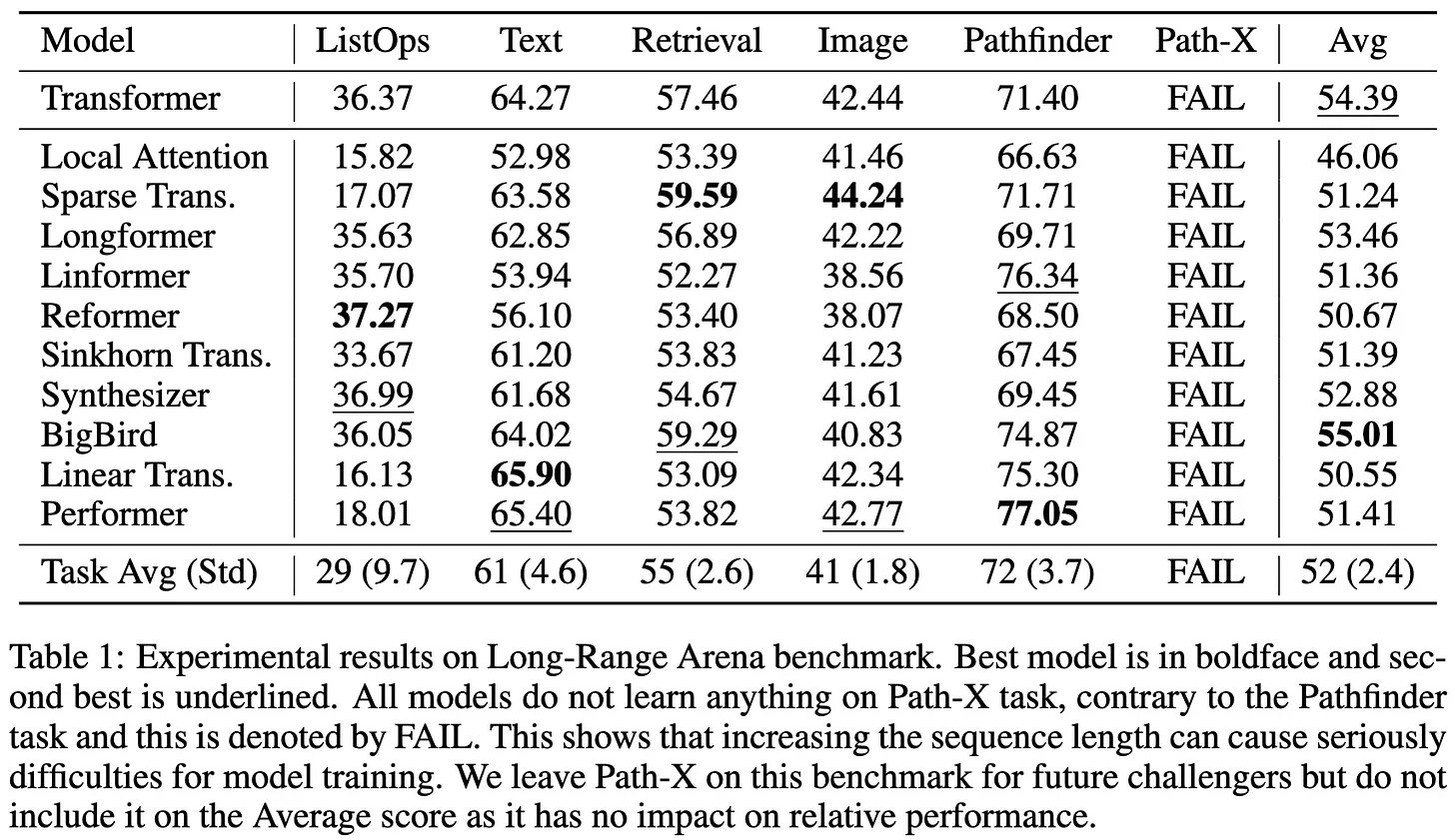

Then @_albertgu's S4 (arxiv.org/abs/2111.00396) happened. They replaced attention with a state-space model using a lot of fancy math. The results were fantastic. [4/14] 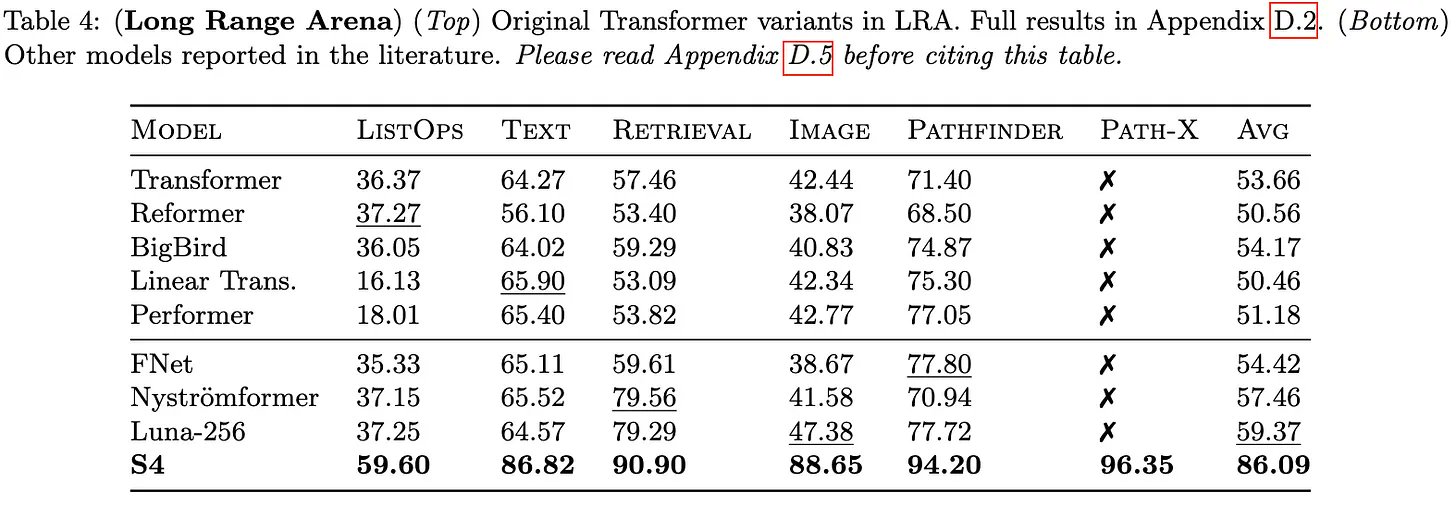

@_albertgu Pretty soon, other state space models like Liquid-SSMs (bit.ly/3gKCqbF), S5 (bit.ly/3TYURYk), and Mega (bit.ly/3ze1fTS) built on these results. Within a year, the Long Range Arena was dominated by state space models. [5/14] 

@_albertgu But it hasn't been clear why state space models work so well. Do we really need to treat the sequence as a discretization of a continuous signal, fit esoteric polynomials, and employ linear algebra tricks to get these great results? [6/14]
@_albertgu According to today's paper, the answer is no. Instead, the reason for state space models' success is that they entail convolving with filters that:
1: are as long as the sequence,
2: weight nearby context more heavily, and
3: have sublinear parameter counts. [7/14]
1: are as long as the sequence,
2: weight nearby context more heavily, and
3: have sublinear parameter counts. [7/14]
@_albertgu I.e., it's not that state space models are great, and happen to be implemented with long convolution kernels.
It's that long convolution kernels are great, and state space models happen to be why we implemented them. [8/14]
It's that long convolution kernels are great, and state space models happen to be why we implemented them. [8/14]

@_albertgu They provide evidence for this in the form of a simple method embodying these properties. Their proposed SGConv constructs convolution kernels as concatenations of successively longer but lower-magnitude sinusoids. [9/14] 

@_albertgu Their method consistently beats S4 and other baselines on the Long Range Arena. It’s also faster and needs less memory at every sequence length. [10/14] 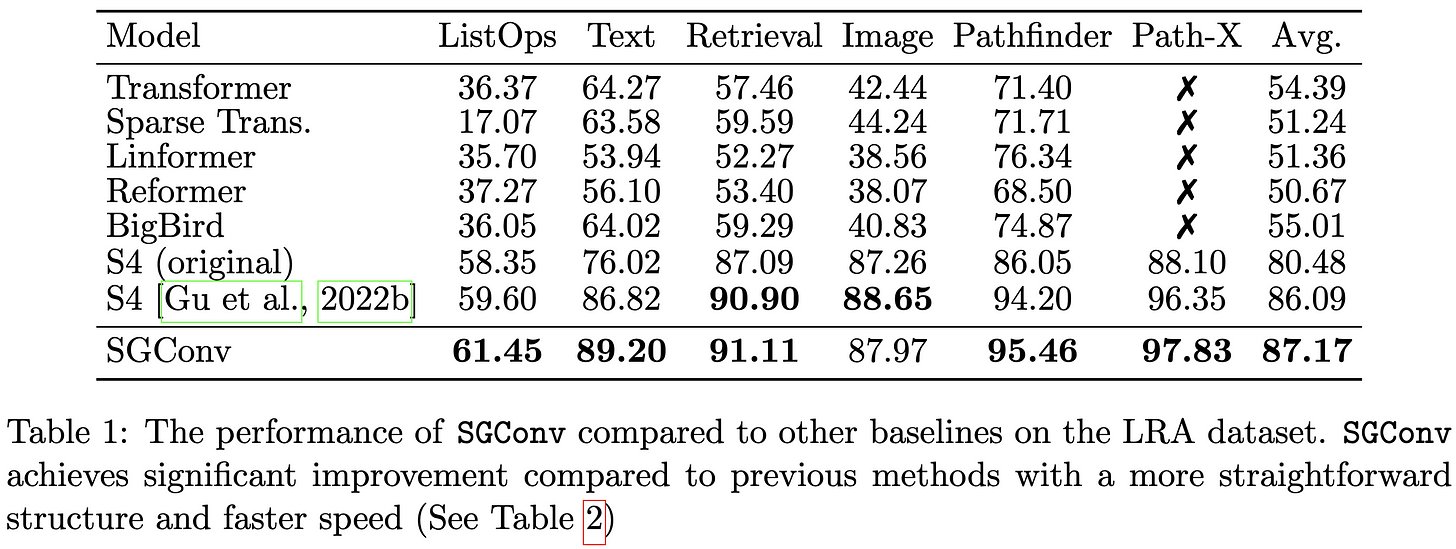
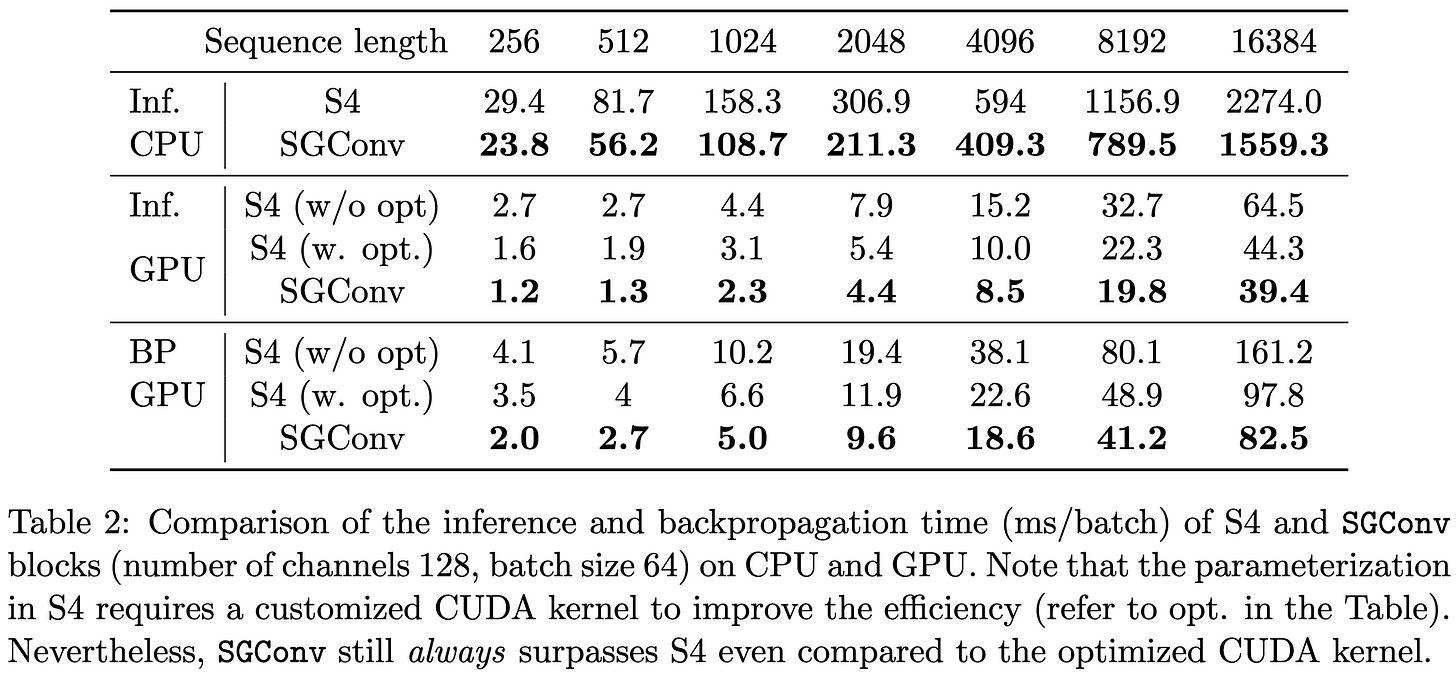



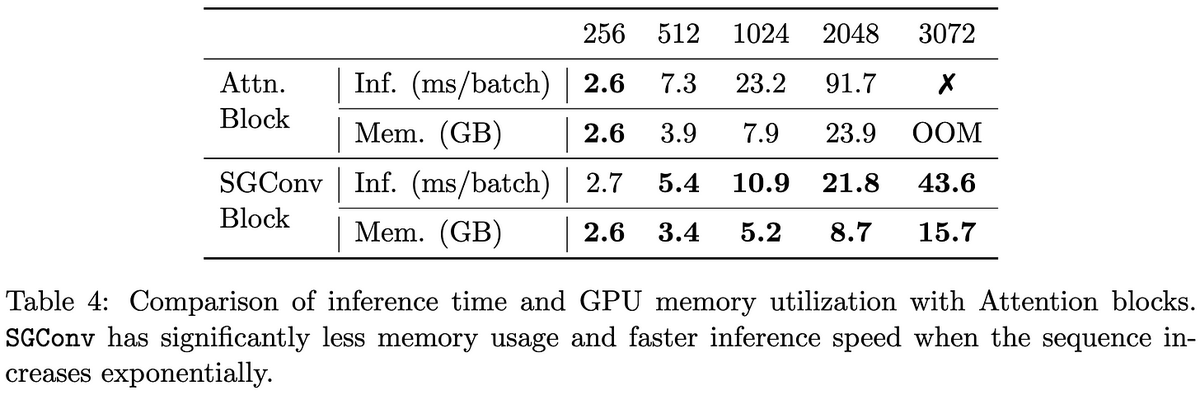
@_albertgu In short, there's a simple CNN that crushes every transformer on a variety of sequence modeling tasks. And the only other methods to come close on this benchmark—state space models—are also CNNs under the hood. [11/14]
@_albertgu Instead of attention being "all we need"...maybe we never needed attention at all? [12/14]
@_albertgu Paper: arxiv.org/abs/2210.09298
If you like this paper, consider RTing this (or another!) thread to publicize the authors' work, or following the authors: @yli3521 @tianle_cai @YiZhangZZZ… [13/14]
If you like this paper, consider RTing this (or another!) thread to publicize the authors' work, or following the authors: @yli3521 @tianle_cai @YiZhangZZZ… [13/14]
@_albertgu @yli3521 @tianle_cai @YiZhangZZZ …@debadeepta
For more paper summaries, you might like following @mosaicml, me, or my newsletter: bit.ly/3OXJbDs
As always, comments and corrections welcome! [14/14]
For more paper summaries, you might like following @mosaicml, me, or my newsletter: bit.ly/3OXJbDs
As always, comments and corrections welcome! [14/14]