Thread by Vedanuj Goswami
- Tweet
- Jul 7, 2022
- #ArtificialIntelligence
Thread
Excited to share our No Language Left Behind project. A single multilingual model capable of translating between any pair across 200+ languages. This long 🧵attempts to discuss some of the technical contributions of NLLB.
(1/n)
research.facebook.com/publications/no-language-left-behind/
(1/n)
research.facebook.com/publications/no-language-left-behind/
(2/n) We take a human-centered approach to scale machine translation to low-resource languages. Our guiding principles:
- Prioritize the needs of underserved communities
- Sharing through open-sourcing
- Being interdisciplinary in our approach
- Being reflexive in our efforts
- Prioritize the needs of underserved communities
- Sharing through open-sourcing
- Being interdisciplinary in our approach
- Being reflexive in our efforts
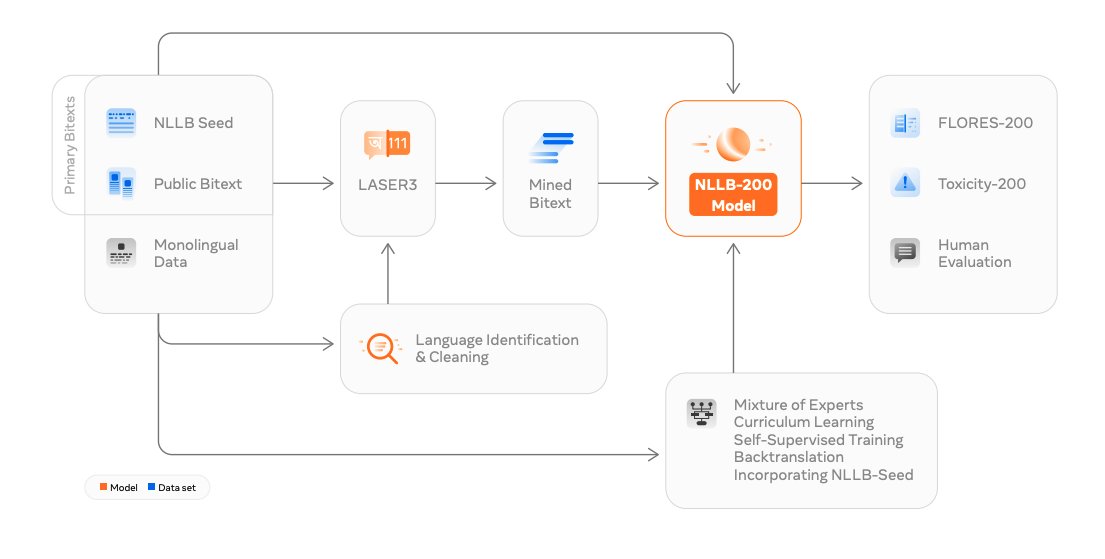
(3/n) For building reliable MT systems, we need benchmarks to measure quality and safety effectively. As a first step towards this, we collected FLORES-200, the first multilingual many-to-many benchmark covering 200+ languages.
github.com/facebookresearch/flores/blob/main/flores200/README.md
github.com/facebookresearch/flores/blob/main/flores200/README.md
(4/n) Next, in order to measure toxicity in translations, we also collected Toxicity-200, an evaluation dataset for toxic words/phrases covering all the languages in FLORES-200.
github.com/facebookresearch/flores/blob/main/toxicity/README.md
github.com/facebookresearch/flores/blob/main/toxicity/README.md
(5/n) To measure OOD generalization, which is another important aspect, we also collected NLLB-MultiDomain, a small dataset containing a set of professionally-translated sentences in News, Unscripted informal speech, and Health domains.
github.com/facebookresearch/flores/tree/main/nllb_md
github.com/facebookresearch/flores/tree/main/nllb_md
(6/n) In order to train models for very low-resource languages, many of which have less than 20-30k aligned parallel samples, we collect NLLB-Seed, a dataset consisting of ~6k parallel data, but high quality and human translated. Quite useful for bootstrapping models. 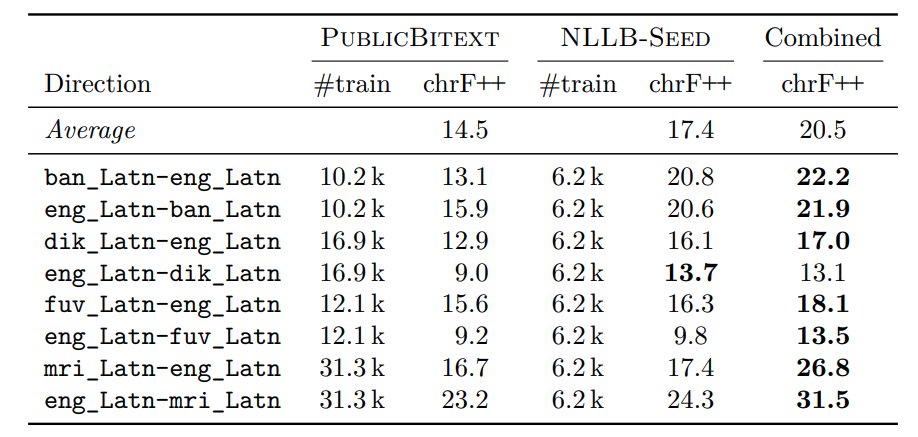

(7/n) Public MT datasets+NLLB-Seed is still not enough to train high quality MT models. So we collect monolingual data from the web and apply improved LID models to distinguish and identify data for all the languages. 

(8/n) Data filtering and cleaning is a super important step which effects the final MT quality. A clean monolingual corpora powers and improves several of the subsequent steps in the NLLB pipeline - mining, backtranslation and self-supervised learning. 
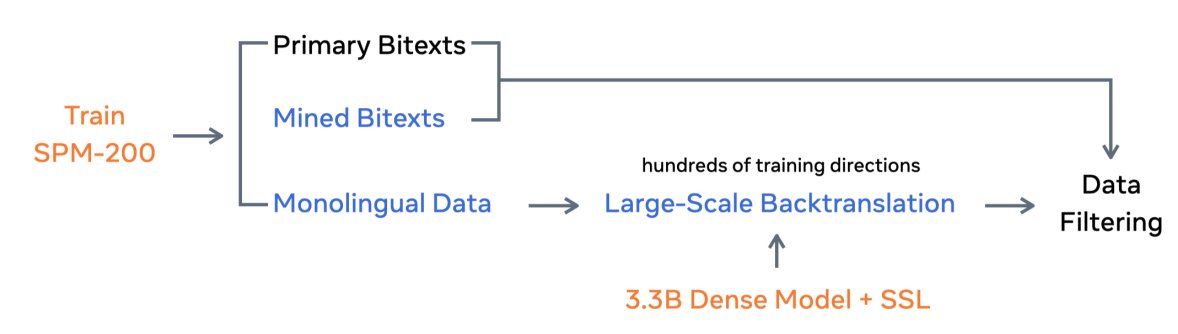
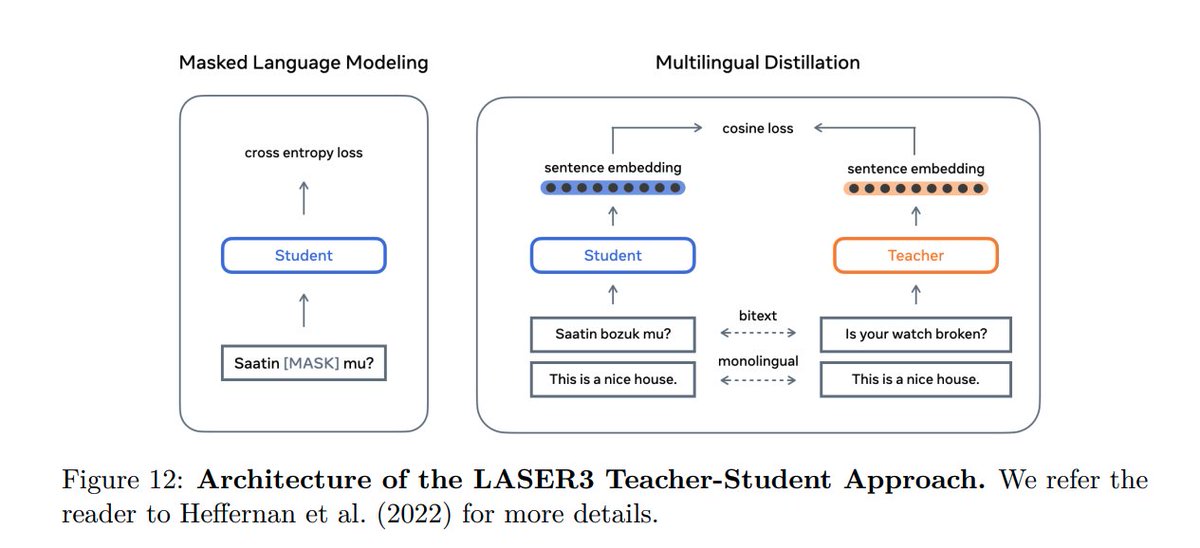
(9/n) We improve data mining with self-supervised training of transformer models and apply teacher-student distillation to further improve the encoders(LASER3). Using this we mine parallel bitexts for 200+ languages and 1500+ directions. 
(10/n) We next attempt at scaling a single multilingual model for all 200+ languages. However due to majority languages being low-resource, data imbalance is very high which causes low-resource languages to overfit. Also more languages == more interference.
(11/n) We improve our models by incorporating strong regularization(MoE dropout), curriculum learning, self-supervised learning and diversifying backtranslation.
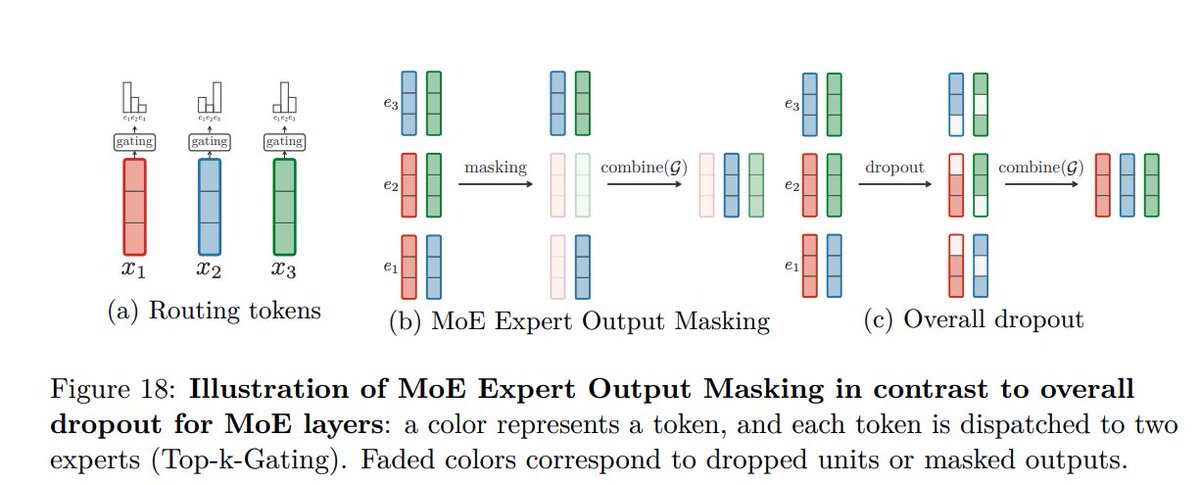
(12/n) We augment Sparsely Gated Mixture of Experts models with Expert Output Masking, improving overfitting considerably compared to a generic overall model dropout. 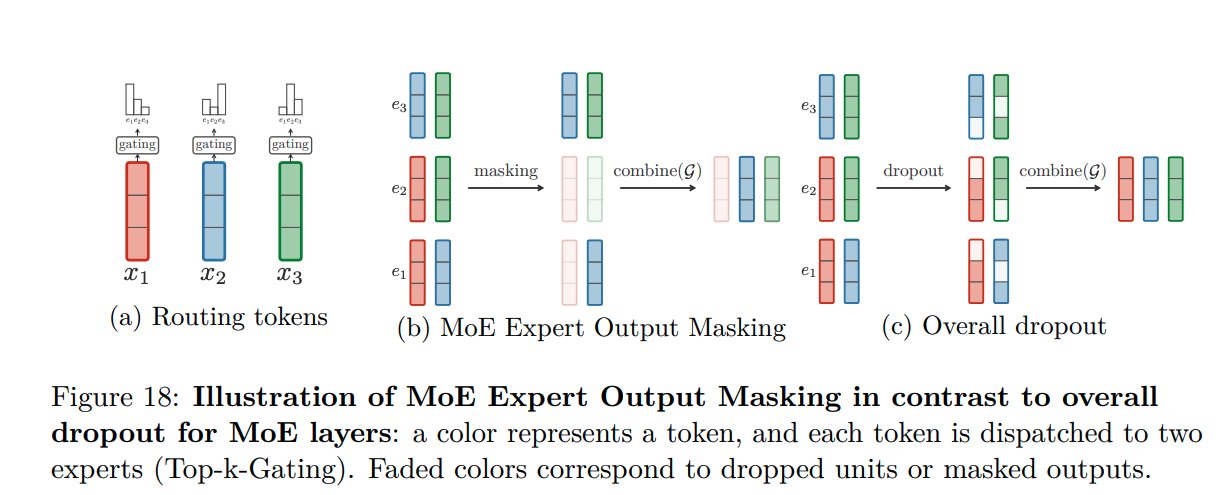
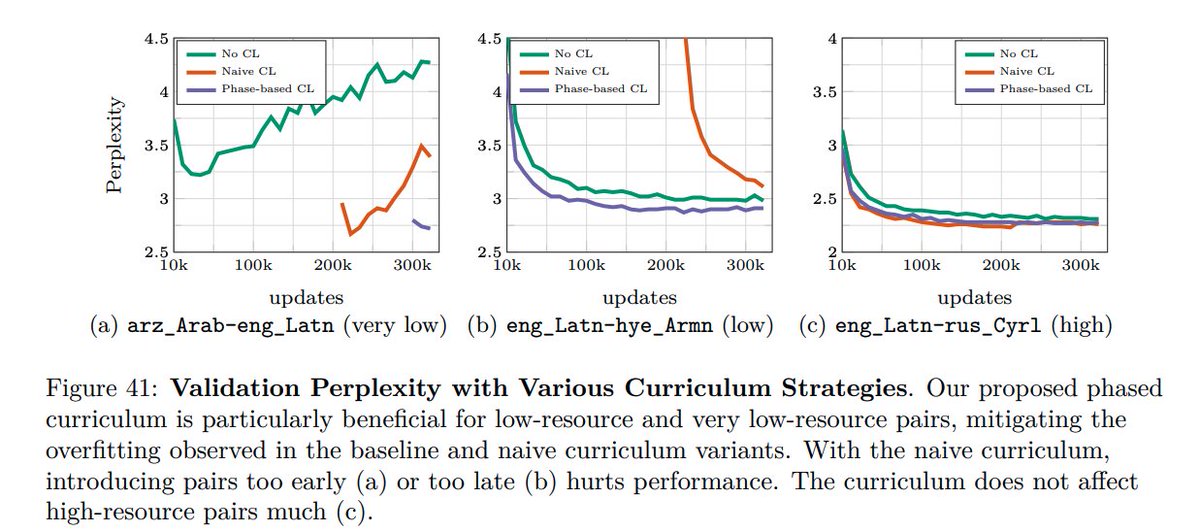
(13/n) We tackle overfitting further with curriculum learning, a phased curriculum, that buckets language pairs based on when they overfit during a no-curriculum training. 
(14/n) Self-supervised objectives like denoising improve model performance when trained in a multitask setup. Improvements are significant when applied on primary+mined data. 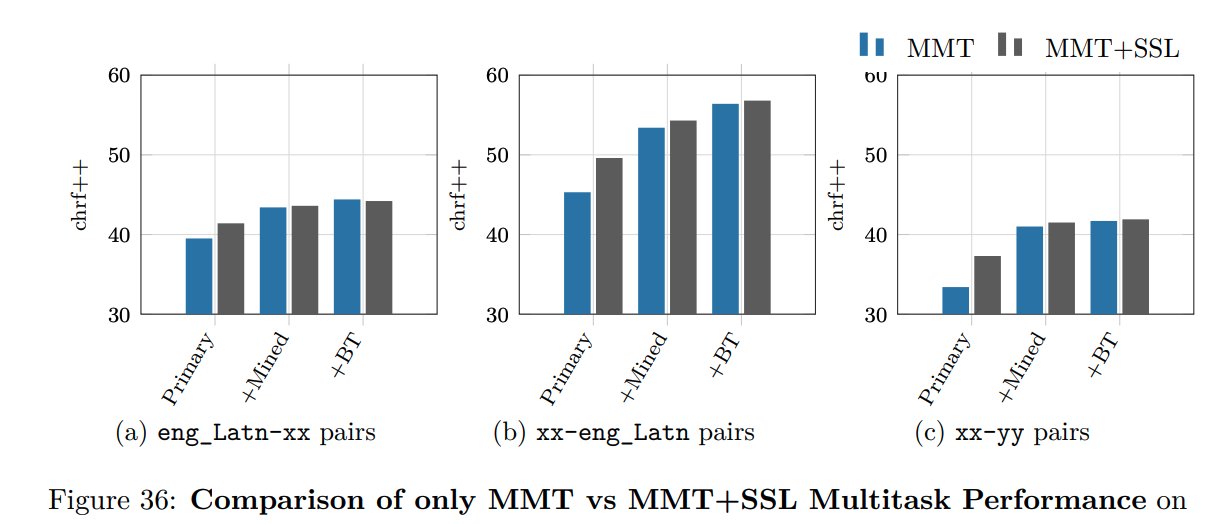
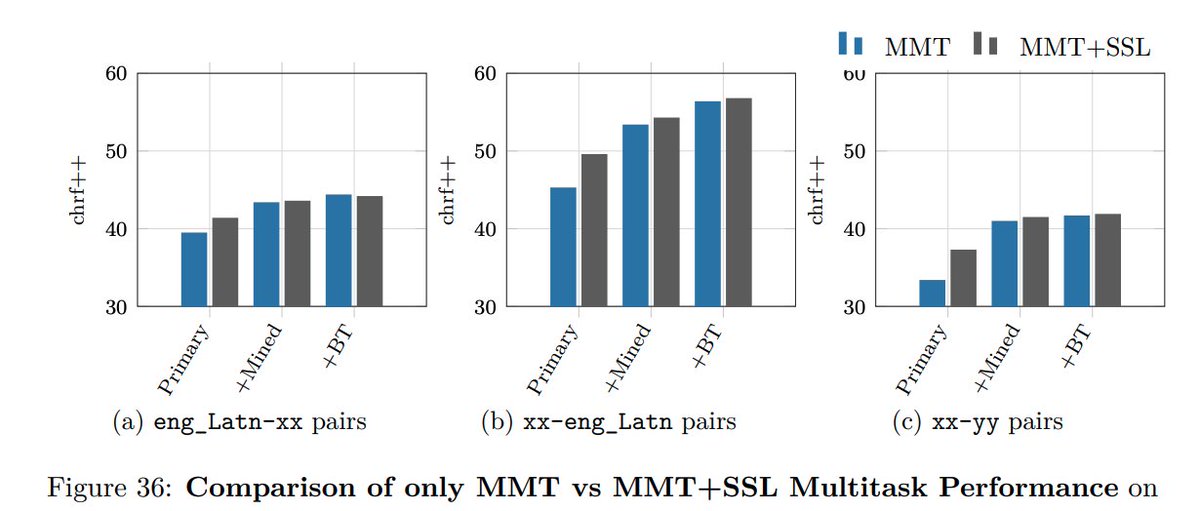
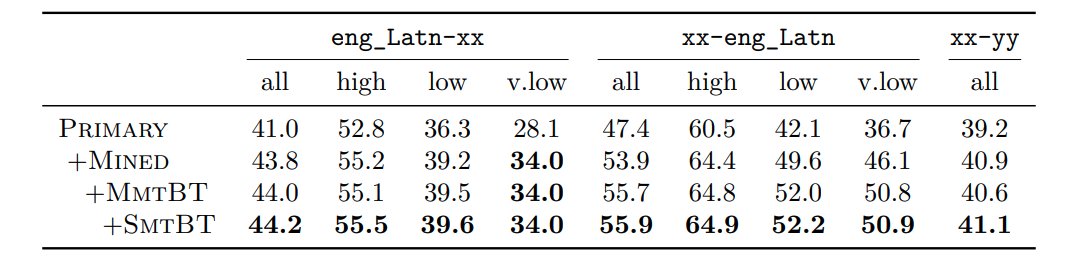
(15/n) Backtranslation from multiple sources helps. We add backtranslated data from Statistical MT models in addition to NMT models to boost performance. Fine-grained tagging of different data sources is beneficial. 
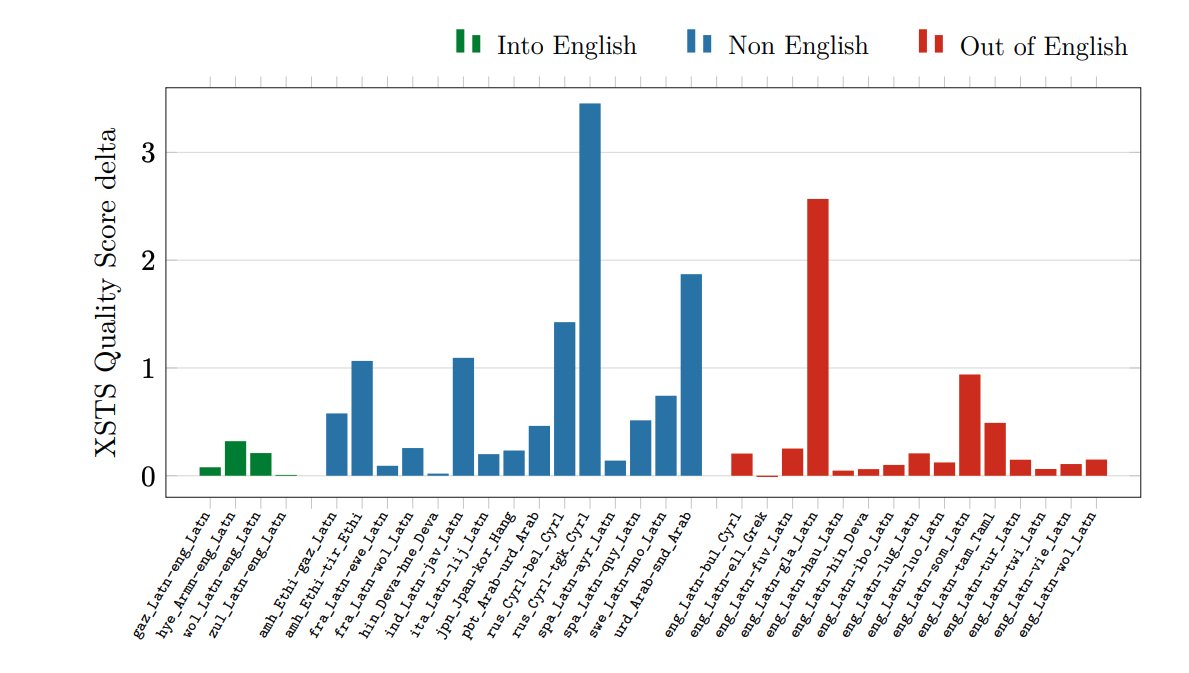
(16/n) We use Crosslingual Semantic
Text Similarity (XSTS) protocol for human evaluations and also evaluate hallucinated and imbalanced toxicity in our model translations.
Text Similarity (XSTS) protocol for human evaluations and also evaluate hallucinated and imbalanced toxicity in our model translations.
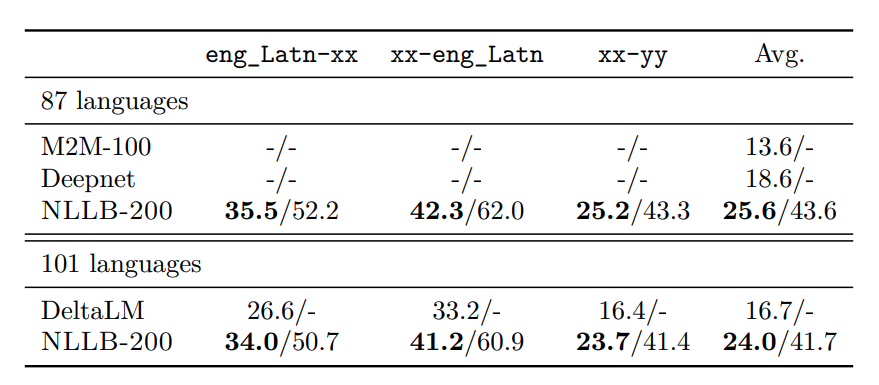
(17/n) Our final model, NLLB-200, a 54.5B Sparsely Gated MoE model outperforms SOTA models on Flores-101 by +44%. Significantly outperforms SOTA on both Indian and African language groups. On non-FLORES MT benchmarks, NLLB-200 shows strong performance. (spBLEU/chrF++) 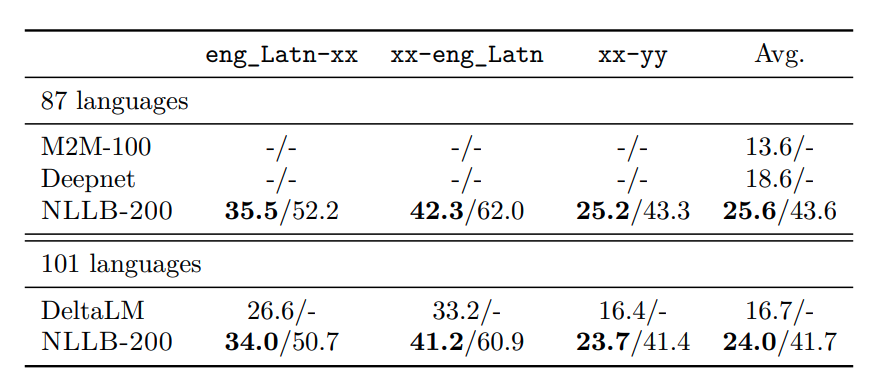
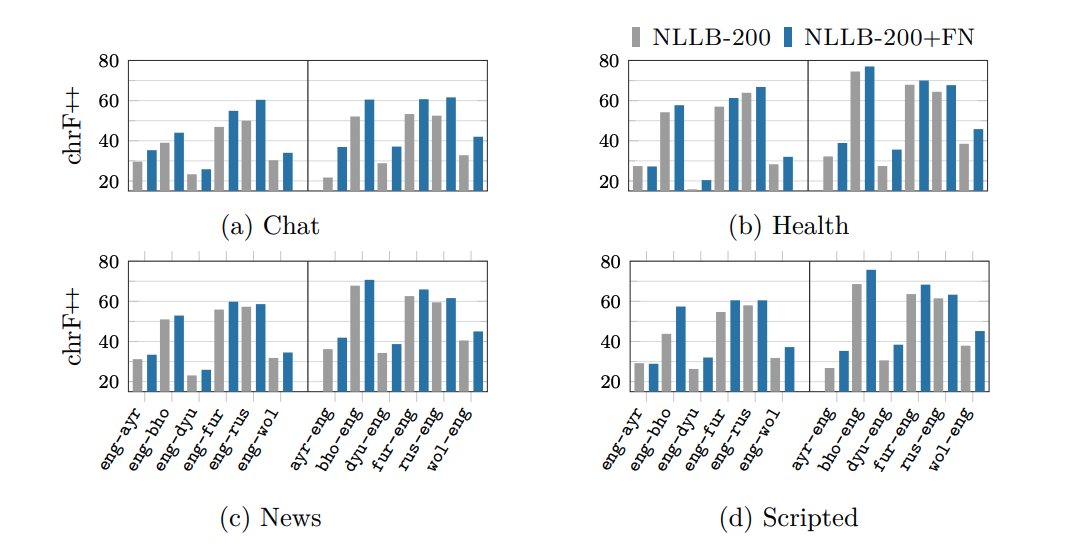
(18/n) Finetuning NLLB-200 on new and unseen domains, often performs reasonably well, showcasing its strong out of domain generalization capability. 
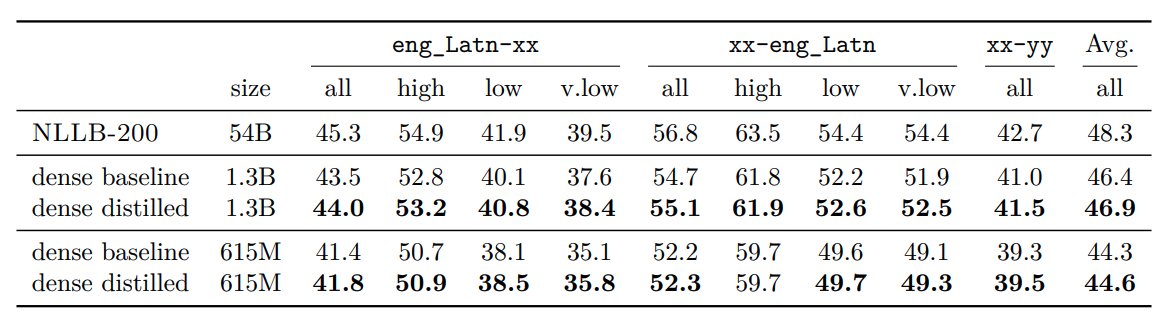
(19/n) Distilled NLLB models are powering real world use cases like helping @Wikimedia editors for content translations. Online distillation of NLLB-200 gives us models much smaller in size but just slightly reduced performance. 
(20/n) We also show results of NLLB-200 and custom/specialized models on multidialectal translations and transliteration tasks.
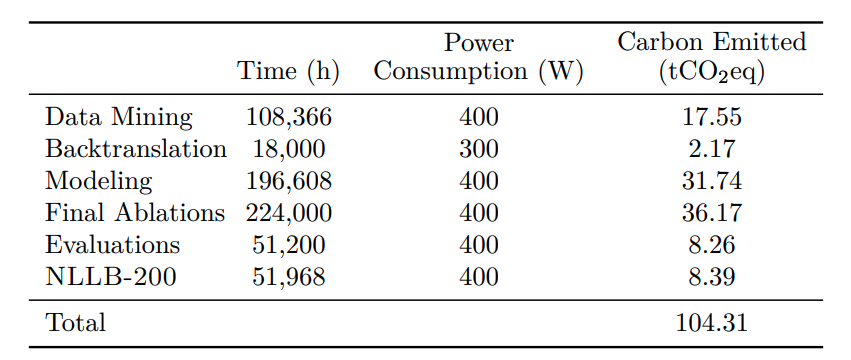
(21/n) We share a detailed analysis of environmental impact of entire NLLB project. Although these are approximate estimates, we try to be comprehensive and show the CO2 emissions for each part of the project. 
(22/n) Finally, the most important aspect of the project for me .. open sourcing everything!
Model: github.com/facebookresearch/fairseq/tree/nllb
Mining: github.com/facebookresearch/stopes
LASER3: github.com/facebookresearch/LASER/tree/main/nllb
Benchmark: github.com/facebookresearch/flores
ai.facebook.com/research/no-language-left-behind/
Model: github.com/facebookresearch/fairseq/tree/nllb
Mining: github.com/facebookresearch/stopes
LASER3: github.com/facebookresearch/LASER/tree/main/nllb
Benchmark: github.com/facebookresearch/flores
ai.facebook.com/research/no-language-left-behind/
(23/n) Here is a cool demo powered by NLLB-200. Soon expanding to many more languages.
nllb.metademolab.com/
nllb.metademolab.com/
(24/n) Huge interdisciplinary collaboration. Check out our blog for more details : ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
w collaborators from @MetaAI (@edunov, @shruti_bhosale , @SchwenkHolger, @melbayad, @LoicBarrault, @jffwng etc.)
w collaborators from @MetaAI (@edunov, @shruti_bhosale , @SchwenkHolger, @melbayad, @LoicBarrault, @jffwng etc.)