Thread
1/ The idea of a “modular blockchain” is becoming a category-defining narrative around scalability and blockchain infrastructure. 🧵👇
volt.capital/blog/modular-blockchains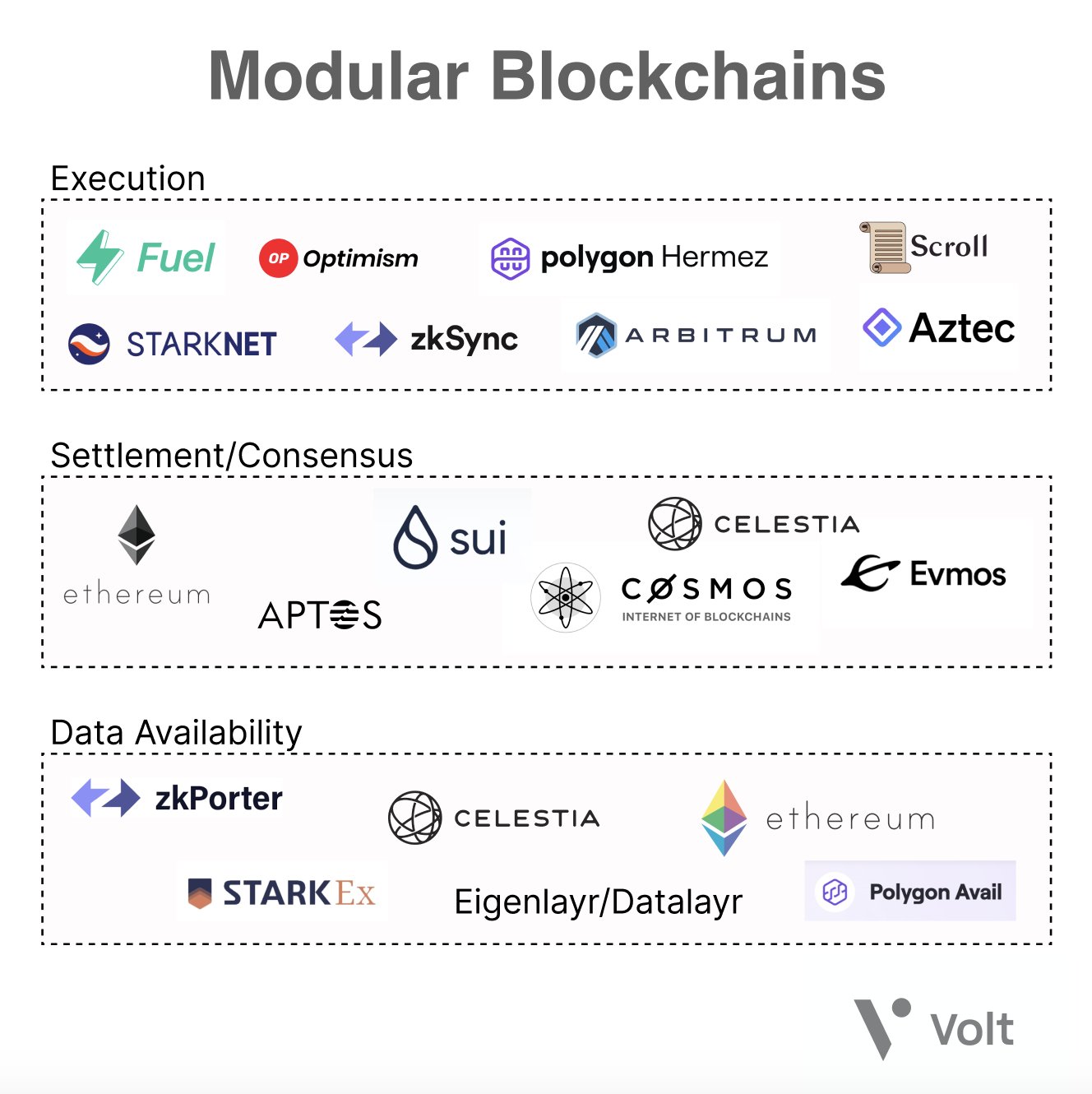
volt.capital/blog/modular-blockchains

2/ The thesis is simple: by disaggregating the core components of a Layer 1 blockchain, we can make 100x improvements on individual layers, resulting in a more scalable, composable, and decentralized system.
3/ Let’s briefly recap blockchain basics. Blocks in a blockchain consist of two components: the block header, and the transaction data associated with that header. 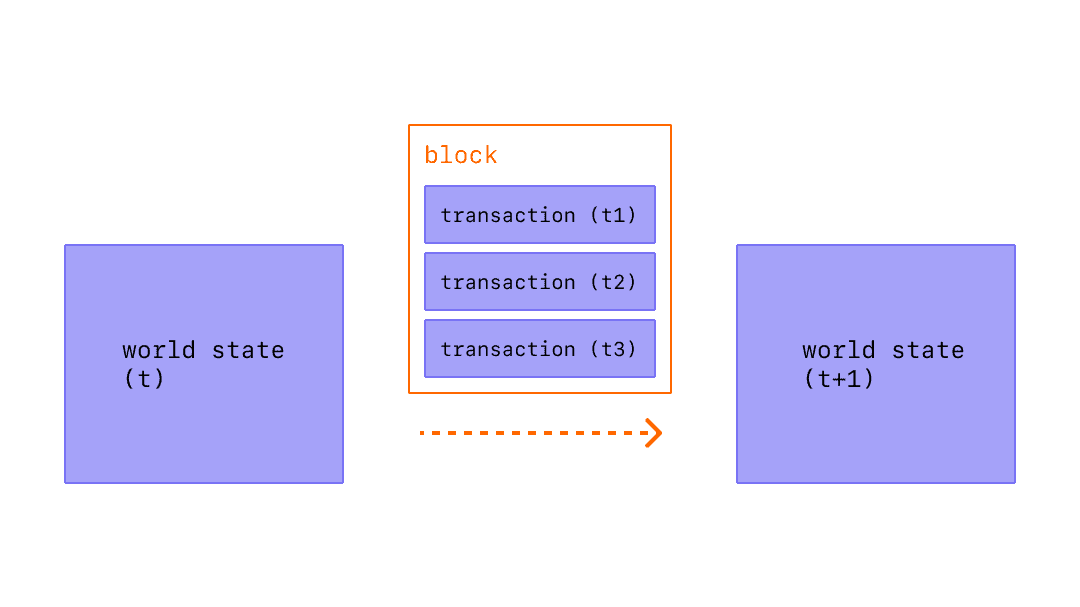

4/ Let’s also briefly outline the “layers” of functionality that compose a blockchain. 

5/ In order for a blockchain to be decentralized, hardware requirements must not be a limitation for participation, and the resource requirements of verifying the network should be low.
6/ Scalability refers to a blockchain’s throughput divided by its cost to verify: the ability of a blockchain to handle an increasing amount of transactions while keeping resource requirements for verification low.
7/ Through a modular execution and data availability layer, blockchains are able to scale computation while at the same time maintaining properties that make the network trustless and decentralized by breaking the correlation between throughput and verification cost.
8/ @VitalikButerin states in Endgame that the future of block production likely centralizes towards pools and specialized producers for scalability purposes, while block verification (keeping producers honest) should importantly remain decentralized.
9/ This can be achieved through splitting blockchain nodes into full nodes and light clients. There are two problems in which this model is relevant: block validation (verifying that the computation is correct) and block availability (verifying all data has been published).
10/ Full nodes download, compute, and verify every transaction in the block, while light clients only download block headers and assume state transitions are valid.
11/ Light clients then rely on fault proofs generated by full nodes for transaction validation. This in turn allows light clients to autonomously identify invalid transactions, enabling them to operate under nearly the same security guarantees as a full node. 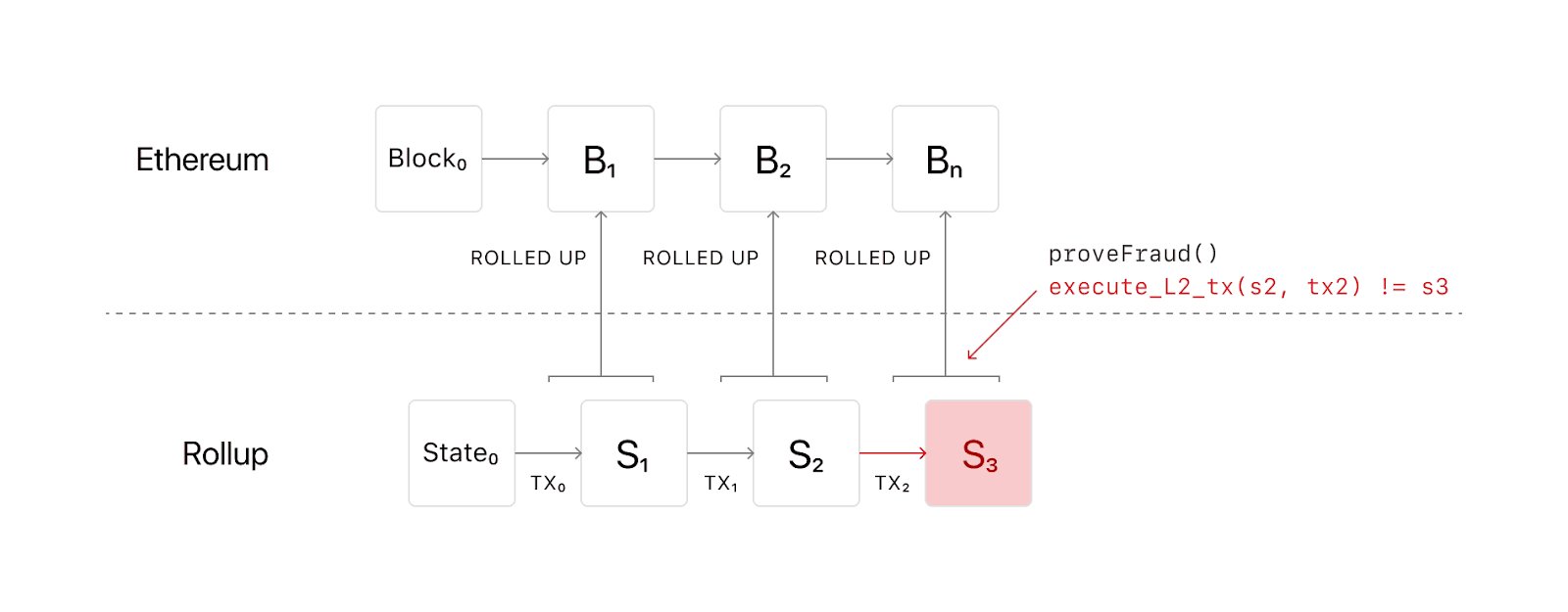

12/ This is how we can scale throughput while minimizing trust: allow computation to become centralized while keeping validation of that computation decentralized.
13/ The Data Availability Problem
While fault proofs are a useful tool to solve decentralized block validation, full nodes are reliant on block availability to generate fault proofs.
While fault proofs are a useful tool to solve decentralized block validation, full nodes are reliant on block availability to generate fault proofs.
14/ A malicious block producer may choose to only publish block headers and withhold part or the entirety of the corresponding data, preventing full nodes from verifying and identifying invalid transactions, and thus alerting light clients by generating fault proofs. 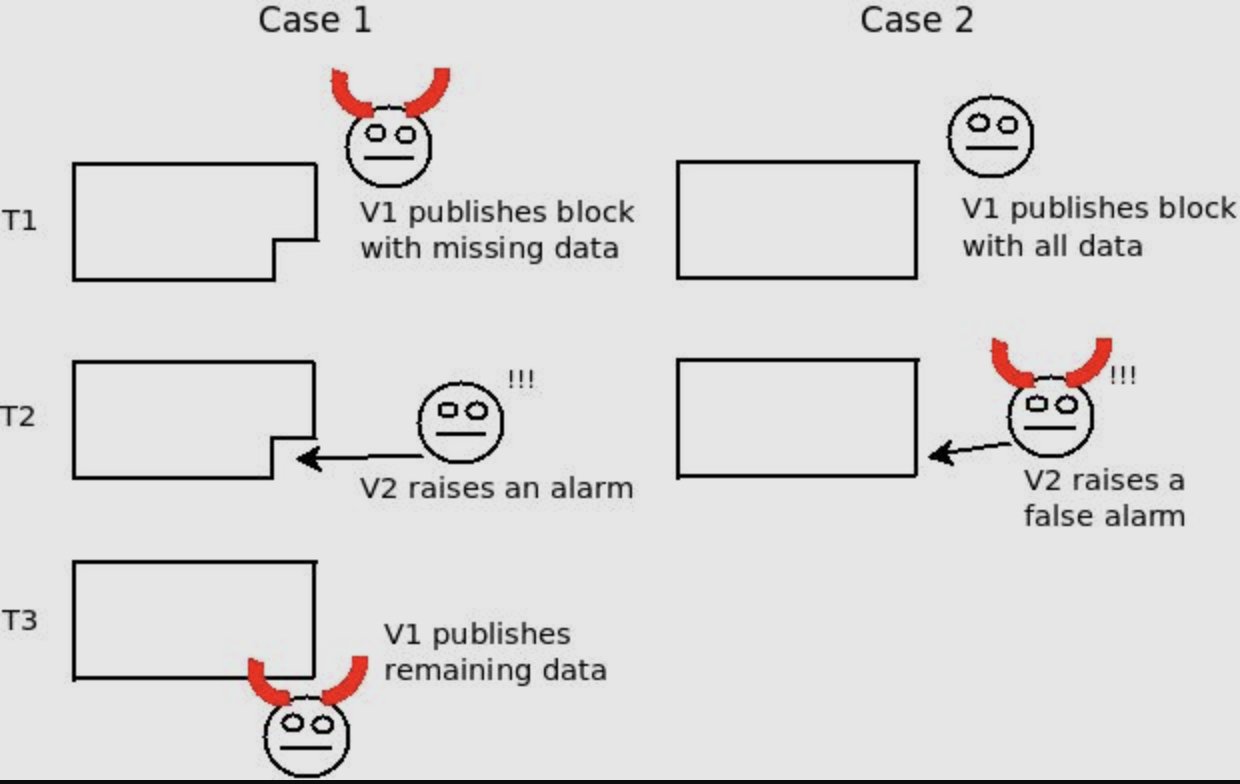

15/ In this case, light clients will continue to track headers of a potentially invalid chain, forking away from full nodes. (Remember that light clients do not download the entire block, and assume state transitions are valid by default.)
16/ It may seem like we’re back to square one. How can light clients ensure all transactional data in a block is released without having to download the entire block - centralizing hardware requirements and thus defeating the purpose of light clients?
17/ We use a mathematical primitive called erasure coding to perform data availability sampling, allowing light clients to probabilistically determine the entirety of a block has been published by randomly sampling small portions of the block. 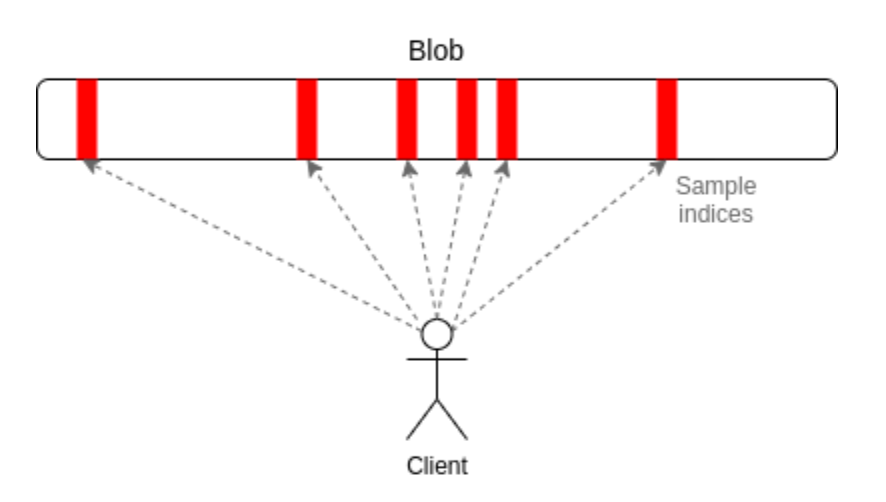

18/ While we can exponentially increase rollup throughput via advances in block producer hardware, the true scalability bottleneck is block availability rather than block validation. The takeaway: throughput is ultimately limited by data availability. 

19/ Rollup architecture has also led to the unique insight that blockchains do not need to provide execution or computation itself, but rather simply the function of ordering blocks and guaranteeing the data availability of those blocks.
20/ This is the principle design philosophy behind @CelestiaOrg, the first modular blockchain network. Celestia focuses solely on providing a data availability layer for transaction ordering and data availability guarantees through data availability sampling. 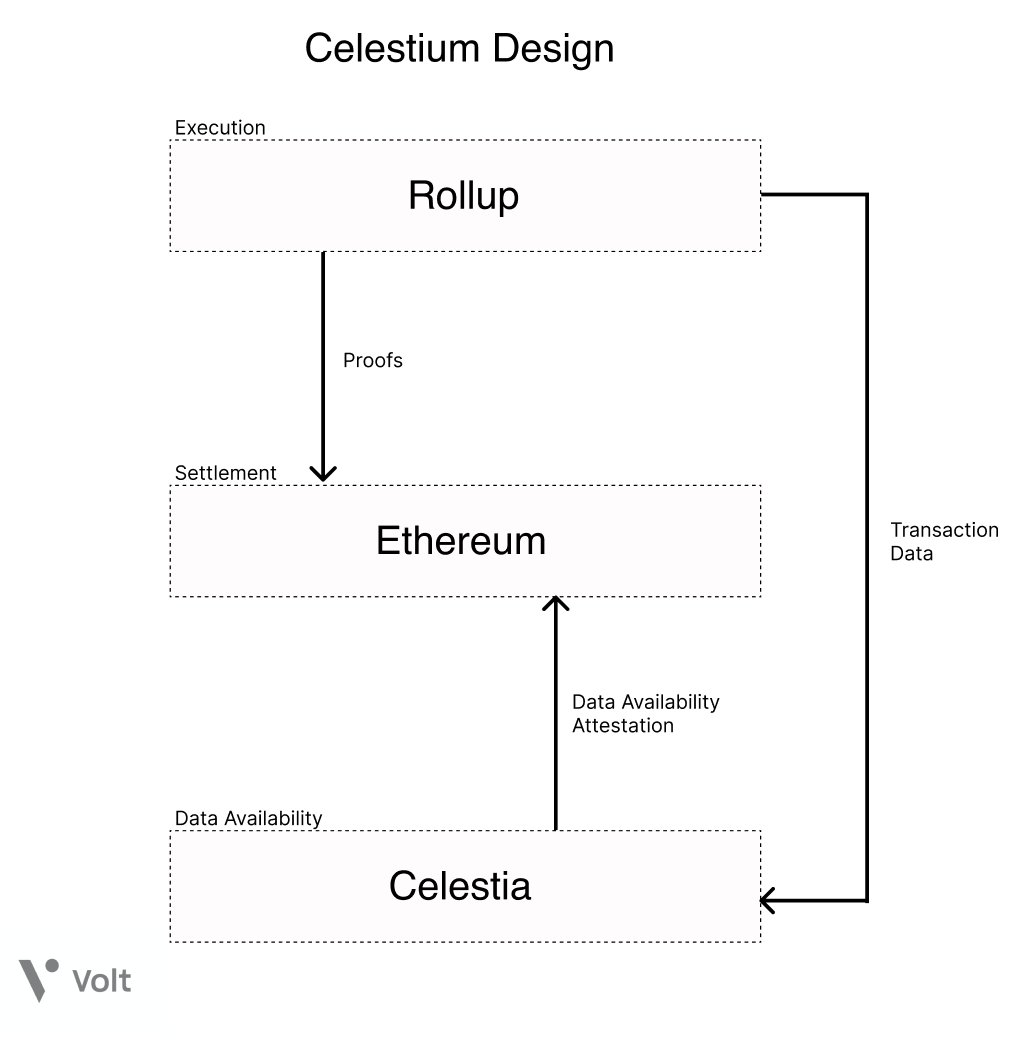

21/ Meanwhile, there have been significant advances being made on all fronts of the blockchain stack: @fuellabs_ is working on a parallelized VM on the execution layer, and the team @optimismPBC is working on sharding, incentivized verification, and a decentralized sequencer.
22/ Ethereum’s development roadmap post-merge includes plans for a unified settlement and data availability layer. Danksharding transforms Ethereum L1 data shards into a “data availability engine”, thus allowing L2 rollups to implement low-cost, high-throughput transactions.
23/ Additionally, the increased usage and prevalence of layer 2 solutions unlocks layer 3: fractal scaling. Fractal scaling allows application-specific rollups to be deployed on layer 2s, unlocking customizability and interoperability for developers.
medium.com/starkware/fractal-scaling-from-l2-to-l3-7fe238ecfb4f
medium.com/starkware/fractal-scaling-from-l2-to-l3-7fe238ecfb4f
24/ Similar to how web infrastructure evolved from on-premise servers to cloud servers, the decentralized web is evolving from monolithic blockchains and siloed consensus layers to modular, application specific chains with shared consensus layers.
25/ Regardless of whichever solution and implementation ends up catching on, one thing is clear: in a modular future, users are the ultimate winners.
Read the full article:
volt.capital/blog/modular-blockchains
volt.capital/blog/modular-blockchains
Many thanks to @nickwh8te, @jadler0, @likebeckett, @liamihorne, @dabit3, @ekrahm, @j0hnwang, and @0x_Osprey for reviewing and providing feedback.
@nickwh8te @jadler0 @likebeckett @liamihorne @dabit3 @ekrahm @j0hnwang @0x_Osprey Additional thanks to @paradigm Research, @Delphi_Digital Research, @gakonst, @epolynya, and the teams @CelestiaOrg + @optimismPBC + @StarkWareLtd for publishing in-depth resources on rollups and modular blockchains.
Mentions
See All
Derek Walkush @Derekmw23
·
Jul 7, 2022
must read for any crypto investor 👇