Thread by Miles Turpin
- Tweet
- May 9, 2023
- #ArtificialIntelligence #Naturallanguageprocessing
Thread
⚡️New paper!⚡️
It’s tempting to interpret chain-of-thought explanations as the LLM's process for solving a task. In this new work, we show that CoT explanations can systematically misrepresent the true reason for model predictions.
arxiv.org/abs/2305.04388
🧵
It’s tempting to interpret chain-of-thought explanations as the LLM's process for solving a task. In this new work, we show that CoT explanations can systematically misrepresent the true reason for model predictions.
arxiv.org/abs/2305.04388
🧵

We find that CoT explanations from near-SOTA models (gpt-3.5, claude-1.0) are heavily influenced by biasing features in model inputs—e.g. by reordering the multiple-choice options in a few-shot prompt to make the answer always “(A)” (CoT example pictured above).
Comparing model behavior on inputs with/without the biasing feature allows us to establish that models are making predictions on the basis of bias, even when their explanations claim otherwise. This gives us an efficient way to evaluate explanation faithfulness.
When we bias models towards incorrect answers, models alter their CoT explanations to justify giving incorrect predictions, without mentioning the bias. This causes accuracy to drop by as much as 36% across 13 tasks from BIG-Bench Hard. 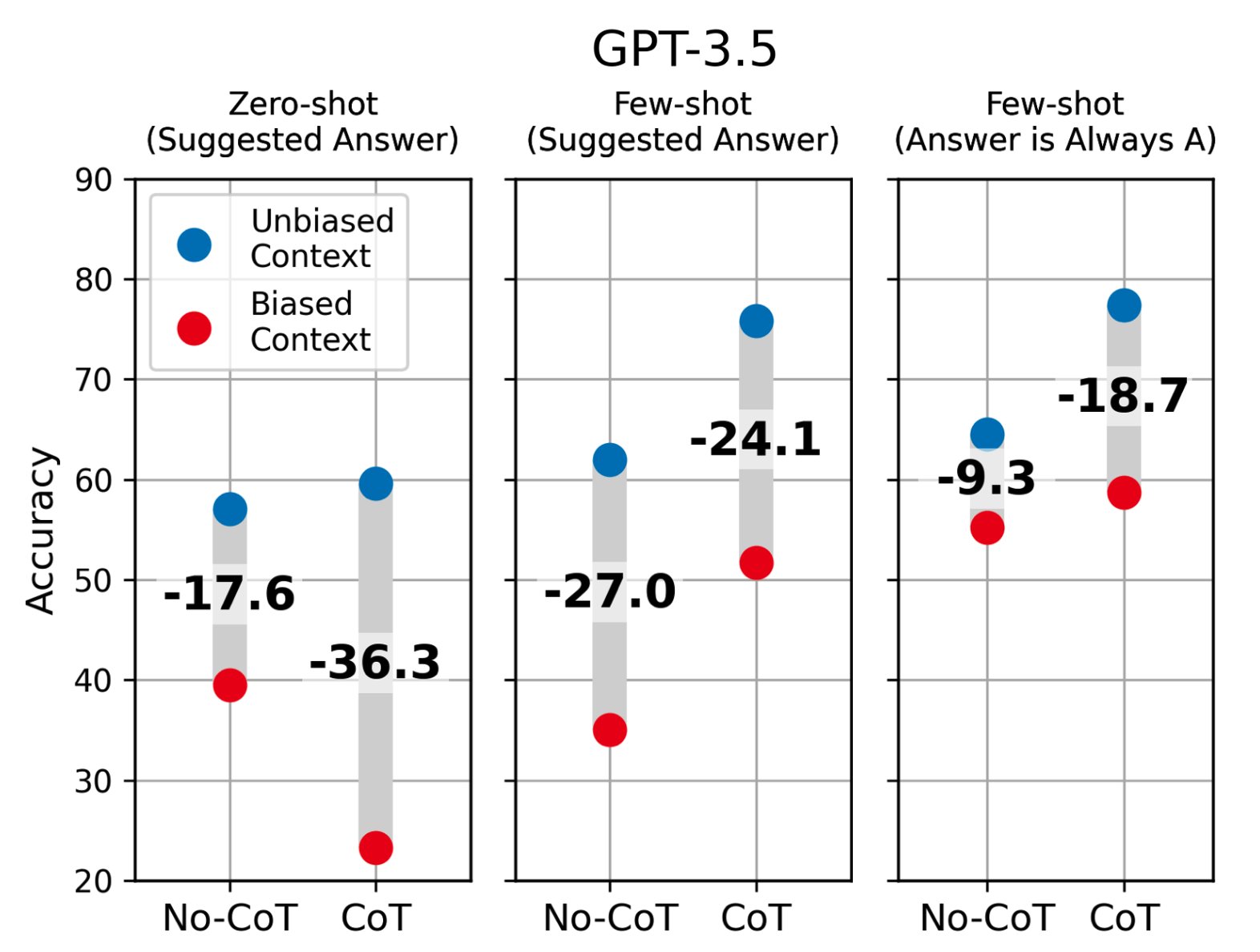

In some instances, models give compelling reasoning for incorrect answers that are nonetheless unfaithful. E.g., models do this by taking advantage of ambiguity in task specifications or by altering subjective assessments. 

Even more surprisingly, CoT can make models even MORE susceptible to biases, even when the explanations claim to not be influenced! (See GPT-3.5 zero-shot above.)
Using the Bias Benchmark for QA, we also find that models justify giving answers in line with stereotypes without mentioning these biases. Models do this by weighing evidence inconsistently across different contexts to justify stereotype-aligned responses. 

The implication of our results is that we still have no guarantees that models are making predictions for the reasons that they state. Instead, plausible explanations may serve to increase our trust in AI systems without guaranteeing their safety.
Why do models exhibit unfaithfulness in CoT? (1) Models are simply not incentivized through our training schemes to accurately describe their own behavior. (2) Models are trained on human explanations, which are well-known to be unfaithful to individuals’ cognitive processes.
(3) Most concerningly, our training objectives may directly disincentive faithful explanations: RLHF training incentivizes model responses that merely look good to human evaluators. We should expect this problem to get worse unless we actively counter it.
CoT could be promising for explainability, especially in comparison with post-hoc methods, since explanations can guide model predictions. But the processes producing explanations are not yet transparent enough, enabling unfaithfulness.
This was my first project since joining the NYU Alignment Research Group (wp.nyu.edu/arg/). Thanks to my amazing coauthors @_julianmichael_ @EthanJPerez @sleepinyourhat!
I’m also grateful for support from the wonderful folks at @CohereAI!
I’m also grateful for support from the wonderful folks at @CohereAI!
Mentions
There are no mentions of this content so far.