Thread by Colin Raffel
- Tweet
- Oct 24, 2019
- #MachineLearning #Naturallanguageprocessing
Thread
New paper! We perform a systematic study of transfer learning for NLP using a unified text-to-text model, then push the limits to achieve SoTA on GLUE, SuperGLUE, CNN/DM, and SQuAD.
Paper: arxiv.org/abs/1910.10683
Code/models/data/etc: git.io/Je0cZ
Summary ⬇️ (1/14)
Paper: arxiv.org/abs/1910.10683
Code/models/data/etc: git.io/Je0cZ
Summary ⬇️ (1/14)
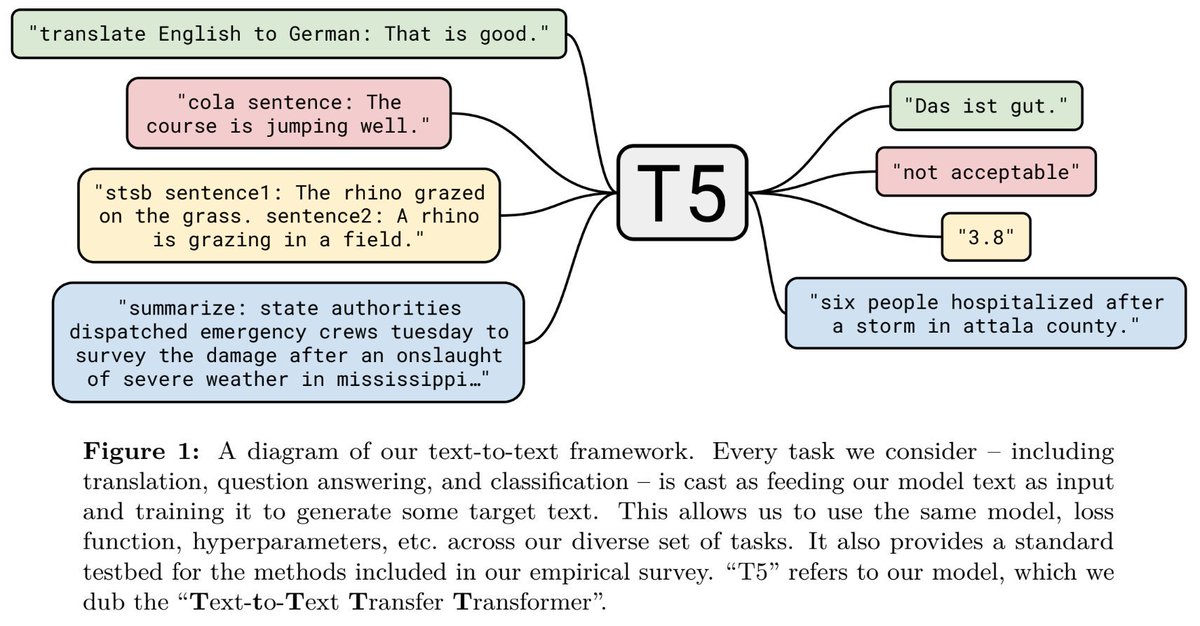
Our approach casts *every* language problem as a text-to-text task. For example, English-to-German translation -- input: "translate English to German: That is good." target: "Das ist gut." or sentiment ID -- input: "sentiment: This movie is terrible!", target: "negative" (2/14)
The text-to-text approach allows us to use the same model, loss function, decoding process, training procedure, etc. across every task we study. It also provides a standard testbed for the many ideas we evaluate in our empirical survey. (3/14)
Transfer learning for NLP usually uses unlabeled data for pre-training, so we assembled the "Colossal Clean Crawled Corpus" (C4), ~750GB of cleaned text from Common Crawl. The code for generating C4 is already available in TensorFlow datasets: www.tensorflow.org/datasets/catalog/c4 (4/14)
For most of the experiments in the paper, we use a basic encoder-decoder Transformer architecture. We found this worked well both on generative and classification tasks in the text-to-text framework. We call our model the "Text-to-Text Transfer Transformer" (T5). (5/14)
For our empirical survey, we first compared different architectural variants including encoder-decoder models and language models in various configurations and with various objectives. The encoder-decoder architecture performed best in our text-to-text setting. (6/14) 

Then, we explored the space of different pre-training objectives. We found that BERT-style denoising objectives generally outperformed other approaches and that a SpanBERT-style (Joshi et al. 2019) objective had the best combination of performance and training speed. (7/14) 

Next, we compared various unlabeled datasets and found that in some cases in-domain pre-training data boosted performance on downstream tasks. Our diverse C4 dataset, however, is large enough that you can avoid repeating any examples, which we showed can be detrimental. (8/14) 

Unsupervised pre-training is standard practice, but an alternative is to pre-train on a mixture of supervised and unsupervised data as in the MT-DNN (Liu et al. 2019). We found both approaches can achieve similar performance once you get the mixing proportions right. (9/14)
Scaling up is a powerful way to improve performance, but how should you scale? We compared training on more data, training a longer model, and ensembling given a specific computational budget. tl;dr: A bigger model is a necessity, but everything helps. (10/14)
Finally, we combine the insights from our study to train five models of varying sizes (up to 11 billion parameters) on 1 trillion tokens of data. We obtained state-of-the-art on GLUE, SuperGLUE, SQuAD, and CNN/Daily Mail, but not WMT translation. (11/14)
I'm particularly happy that we beat the SoTA on SuperGLUE by 4.3% and are within spitting distance of human performance (88.9 vs 89.8). SuperGLUE was designed to only include tasks that were easy for humans but hard for machines. (12/14)
This work was a collaboration between an incredible team including Noam Shazeer, @ada_rob, @katherine1ee, @sharan0909, Michael Matena, @zhouyanqi30, @kongkonglli, and @peterjliu. (13/14)
All of our code, pre-trained models, and datasets are already online, see github.com/google-research/text-to-text-transfer-transformer for more details. Please reach out if you have any questions or suggestions! (14/14)