Thread
Neural nets are often thought of as feature extractors. But what features are neurons in LLMs actually extracting? In our new paper, we leverage sparse probing to find out arxiv.org/abs/2305.01610. A 🧵: 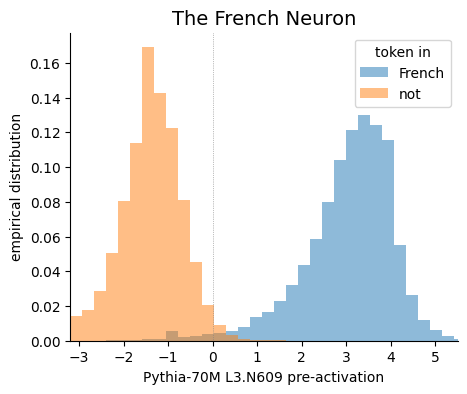

One large family of neurons we find are “context” neurons, which activate only for tokens in a particular context (French, Python code, US patent documents, etc). When deleting these neurons the loss increases in the relevant context while leaving other contexts unaffected! 

But what if there are more features than there are neurons? This results in polysemantic neurons which fire for a large set of unrelated features. Here we show a single early layer neuron which activates for a large collection of unrelated n-grams. 

Early layers seem to use sparse combinations of neurons to represent many features in superposition. That is, using the activations of multiple polysemantic neurons to boost the signal of the true feature over all interfering features (here “social security” vs. adjacent bigrams) 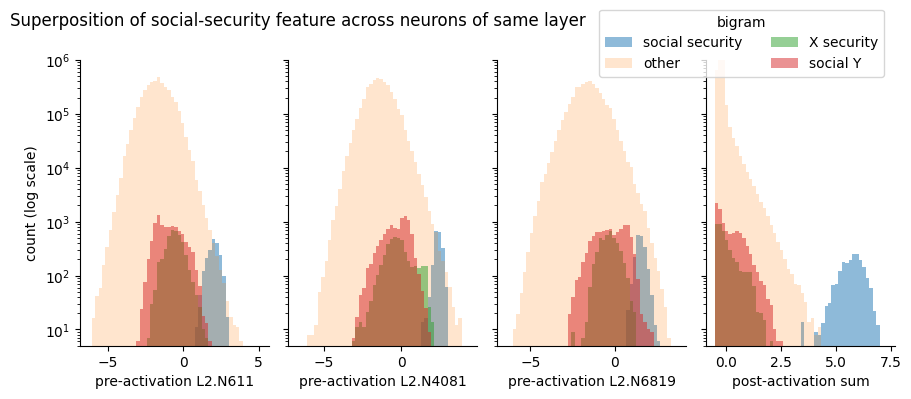

Results in toy models from @AnthropicAI and @ch402 suggest a potential mechanistic fingerprint of superposition: large MLP weight norms and negative biases. We find a striking drop in early layers in the Pythia models from @AiEleuther and @BlancheMinerva. 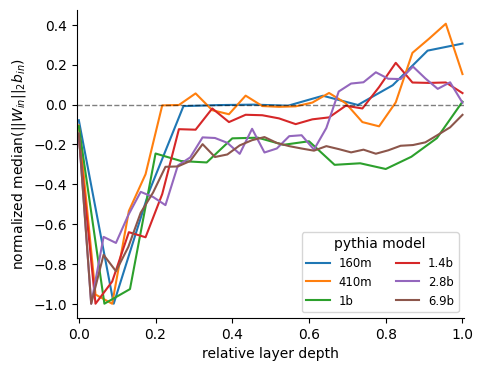

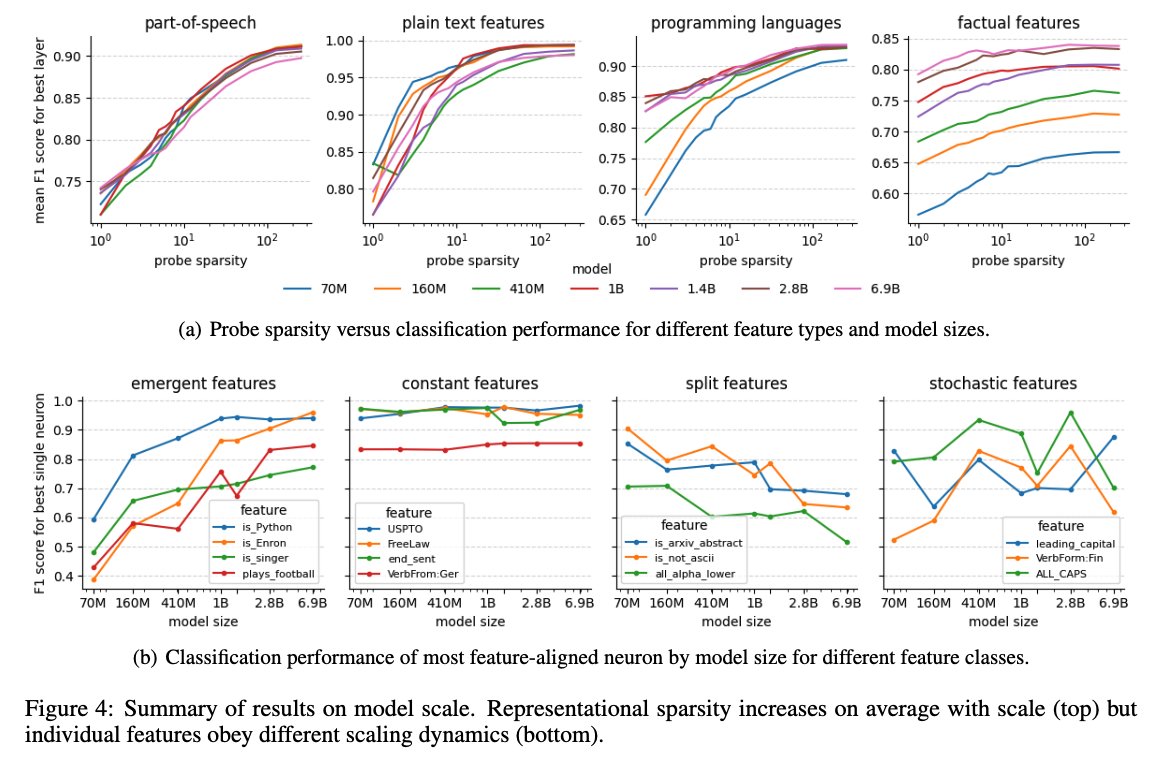
What happens with scale? We find representational sparsity increases on average, but different features obey different scaling dynamics. In particular, quantization and neuron splitting: features both emerge and split into finer grained features. 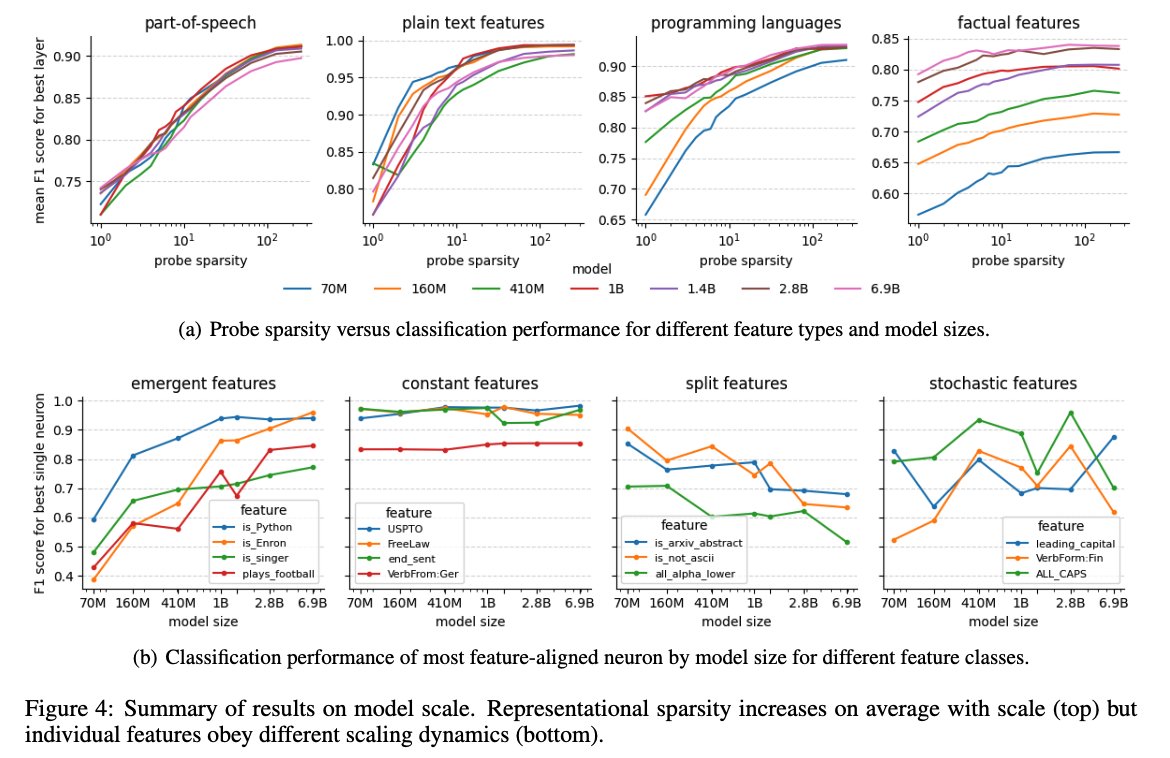
While we found tons of interesting neurons with sparse probing, it requires careful follow up analysis to draw more rigorous conclusions. E.g., athlete neurons turn out to be more general sport neurons when analyzing max average activating tokens. 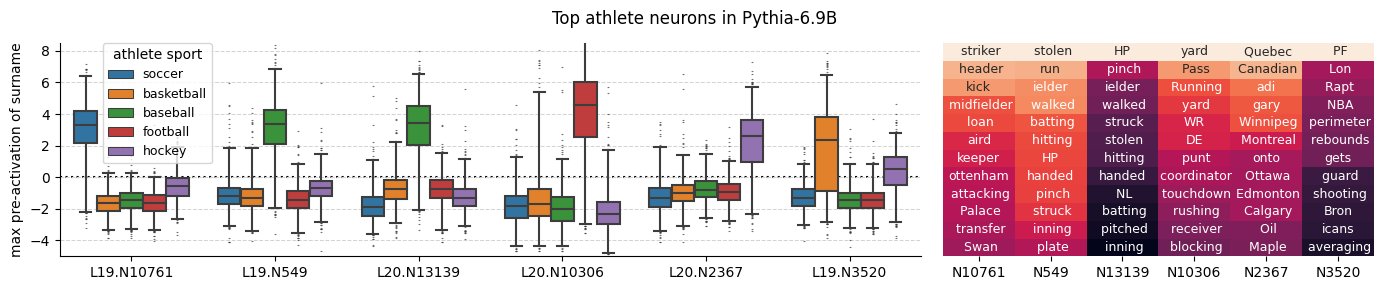

Precision and recall can also be helpful guides, and remind us that it should not be assumed a model will learn to represent features in an ontology convenient or familiar to humans. 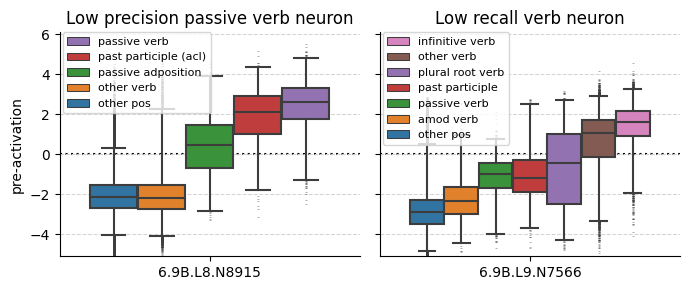

That said, more than any specific technical contribution, we hope to contribute to the general sense that ambitious interpretability is possible: that LLMs have a tremendous amount of rich structure that can and should be understood by humans!
This paper would not have been possible without my coauthors @NeelNanda5, Matthew Pauly, Katherine Harvey, @mitroitskii, and @dbertsim or all the foundational and inspirational work from @ch402, @boknilev, and many others!
Read the full paper: arxiv.org/abs/2305.01610
Read the full paper: arxiv.org/abs/2305.01610
Mentions
There are no mentions of this content so far.