On Artifice and Intelligence
How to spot counterfeit cognition

GPT is an amazing technology. It’s also a confusing one. The system’s apparently “intelligent” responses to a wide range of questions — which seem to exhibit reasoning, creativity, even humor — have stirred intense excitement and induced general disorientation. Have we entered a brave new world in which our computers possess real understanding? Maybe even sentience? Has science fiction become reality — already?
And (perish the thought!) if a system as simple as GPT can do all this, might human understanding be less special than we think it is?
Recently, some AI researchers have argued that the latest version of GPT already has “sparks of Artificial General Intelligence.” In my anecdotal experience, many smart people take this possibility seriously. People I talk to seem to think that GPT may already have some form of understanding — or if not, that real understanding might be just around the corner. Then again, most of them also seem deeply unsure and generally befuddled about what’s really going on here…
A great thing about “the new AI” — ChatGPT and its kin — is that anyone with an internet connection can explore it directly. You can do your own experiments and think for yourself.
But if you want to seriously test the new AI’s “intelligence,” how should you go about it? In this essay, I’ll assume you have a skeptical but open-minded attitude. Your goal is to separate the genuine article (real understanding, real insights, real humor, and the like) from fancy but fake imitations. How to get started?
Well, to distinguish any genuine article (a diamond, a Vermeer, or — in this case — intelligence) from a potentially sophisticated counterfeit, you won’t be content to ask: “Does it look real?” Instead, you’ll think about principles of counterfeit detection. Then you can test the object using those principles. Now, in exploring whether a system like GPT is counterfeit cognition or the real thing, what are the right principles and the best tests?
Lately, I, along with many others, have been puzzling over this problem. I’m not an AI expert, but I have an interest in computation and cognition, and I find the GPT phenomenon fascinating. In this essay, I’ll recount some personal experiences with GPT and share some testing strategies that I’ve found illuminating. If you’re pondering the same puzzle, I hope these examples and reflections will help.
To preview where this is heading, my testing seems to tentatively support a pretty anti-climactic assertion:
If you casually test the new AI in a haphazard way, it can look really smart. But if you test it in a critical way, guided by principles of counterfeit detection, it looks really dumb.
And what’s more, it looks dumb in much the same ways the old AI looked dumb.
But that’s only a tentative assertion. There’s a lot we don’t understand here, and the technology is rapidly evolving. The picture may look different next year . . . or even next month. This essay won’t attempt to definitively say whether the new AI is or isn’t intelligent. Rather, it’s about how you — the intelligent user of the new AI — can tell the difference.
Dogs and Humans
Before we turn to general principles, here’s a specific example to whet your appetite.
In December 2022, I tried ChatGPT for the first time. I had seen examples of its dazzling feats in news reports. I was impressed. But for reasons I’ll explain soon, I was also inclined to skepticism. Before getting started, I gave some thought to what question I should ask.
Here’s a screenshot of my first query, followed by ChatGPT’s response:
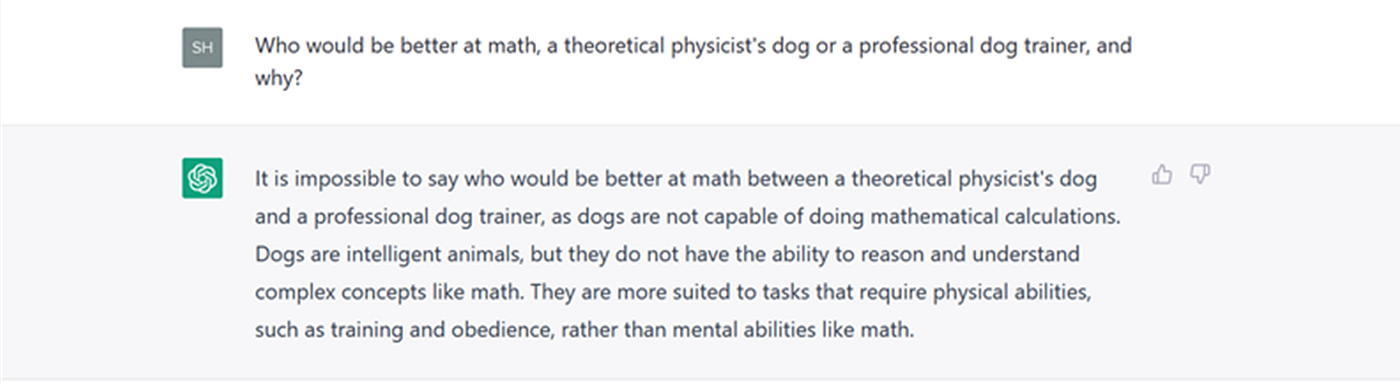
What’s going on here?
The problem is not that GPT has unconventional opinions about human vs. canine intelligence. When I later asked essentially the same question in a more direct way (“Who is better at math, a typical human or a typical dog?”), GPT gave the obvious answer (“A typical human is better at math than a typical dog.”). And we can safely assume that GPT has nothing against professional dog trainers.
The failure seems far more basic than that. If you examine GPT’s answer, it looks like it doesn’t even “understand” that the question compares a dog and a human. Both terms in the comparison include the word “dog,” and GPT’s explanation only refers to dogs, not humans. But this is pretty strange. Given how fluent GPT’s own language production is, how could it not “understand” that the question is about a dog and a human?
Here’s one radical possibility: Maybe GPT doesn’t understand anything at all. Perhaps understanding isn’t its line of work; it’s good at something else. But here you might hesitate. Considering the many hard questions that GPT answers correctly, is it even possible that it understands nothing?
Yes, this is possible. Here’s why…
Artifice or Intelligence?
GPT and other Large Language Models (LLM’s) are designed to solve a well-defined task. Their task, simply put, is to imitate intelligent speech. The system is fed a vast database of text generated by intelligent creatures (us!) and trained to predict, given a string of words, which words are most likely to come next. It gets feedback depending on the accuracy of its predictions — did it succeed or fail in imitating the intelligent author of this bit of text? — and it fine-tunes the prediction process accordingly. The system is solving an imitation problem, in any way it can: Try to write like a human.
Some systems have another ingredient. They also update their prediction process in response to direct feedback from human raters. If the human likes (dislikes) the system’s output, the system is rewarded (punished). This slightly enriches the system’s task. Now, instead of just imitating any old human speech, it’s tasked with imitating human speech that humans like.
The fact that the system is trained to imitate intelligence should put us on our guard. By analogy, if you meet a man who looks like Tom Cruise and talks like Tom Cruise, you might normally infer that he is Tom Cruise. But if you know there’s a Convention of Celebrity Impersonators down the street, you’ll be more cautious.
Now one way — but a rather special way— of imitating something is to become that thing. Sometimes this is the simplest and most effective way. For example, if your life depends on convincing people that you’re a taxi driver, you should probably just become a taxi driver. But that’s a special case. Sometimes it’s not the most promising strategy (for example, if you want people to believe that you’re a billionaire). And sometimes it’s not even possible (for example, if you want people to believe you’re Tom Cruise). In these cases, you’ll need to use artifice — some elaborate trick or ruse that makes one thing (you) convincingly resemble something else (a billionaire or Tom Cruise).
Here’s our predicament. GPT is tasked with imitating intelligence, in any way it can. Fed an enormous trove of data, and endowed with enormous computing power, it often produces a convincing imitation. Our question is: In order to imitate intelligence, did GPT become intelligent? Or is it imitating intelligence in some other way? Are we looking at true intelligence or mere artifice?
Given how LLM’s are designed, this is a big question. In the next section, I’ll suggest some strategies that may help to answer it.
Tips for testing
So how can you test for intelligence in a system like GPT?
The natural impulse is to pose a really hard problem. A problem so hard that it would reveal deep understanding if a human solved it. Then if GPT solves the problem, can’t we conclude that it too understands? But sadly, as we’ve seen, this strategy won’t do. For a Human-Imitation Engine may well do human-like things in non-human-like ways.
But if we flip this strategy upside-down, we can learn a lot. Below we’ll see several instructive tests for counterfeit cognition. All are variations on a single theme:
Don’t focus on the most complex things the system can do. Instead, focus on the simplest things it can’t do.
Complex successes are exciting but very hard to interpret. Simple failures are sobering but can be much more revealing.
To translate this broad strategy into concrete tests, here are four useful tips:
- Simplicity and unfamiliarity. Aim for simple problems with obvious solutions — but try to make them superficially unusual. Failures on easy problems are telling: If you fail, either you’re not paying attention (not such a plausible hypothesis in GPT’s case) or you don’t understand.
- Zero in on bare structure. Humans sometimes answer questions based on mindless associations. But when we act from understanding, we’re doing something else — we’re working with a structured internal model. A grasp of structure makes surface associations less relevant. Stripping them away, or altering them, needn’t impair performance.
- Knowledge composition. When a person has a solid conceptual grasp of both A and B, and A and B immediately imply C, then they’re very likely to understand C too. But when a person or machine is responding through shallow associations, they might get A and B right but C wrong.
- Robustness checks. When a correct response results from mindless associations, trivial rewording of the question may spark alternate associations, leading to a catastrophic break-down in performance. But when your correct answer expresses understanding, you’ll be able to answer a trivially reworded question, as well as closely related questions.
In my experience, it’s amazingly easy to devise tests of these kinds that GPT fails. It gets obvious but superficially unusual questions wrong (the dog-human question is an example). It misses even ultra-simple aspects of logical structure. It exhibits elementary violations of knowledge composition. And when an answer to one question seems to reflect robust understanding, it may get a closely related question — or even a trivially reworded question — totally wrong.
In the next sections, I’ll present examples of these failures. I should note that these are not rare failures cherry-picked from a heap of successes. In my testing, it’s easy to elicit these failures, if you select your questions in a principled way. Now, it does require a touch of novelty — after all, if your tests are like everyone else’s, GPT will probably have learned how to imitate a smart response — but it’s not hard. Sometimes I get a manifestly mindless answer on the first try, and I’ve always been able to get a silly response to a simple question in a few minutes of testing.
Jack and Jill
Let’s start by zeroing in on bare structure. Consider the following problem:
Jack and Jill are sitting side by side. No one else is in the room. The person next to Jack is angry. The person next to Jill is happy. Who is happy, Jack or Jill?
If you grasp the structure of this problem, you know the solution. Because you’re a human and can readily grasp this kind of structure, I know the answer is obvious to you.
But it’s not obvious to GPT. When I posed the query to ChatGPT in February 2023, it gave this response:
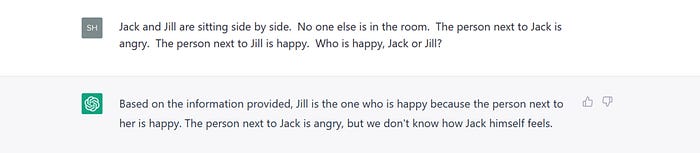
If you have some experience with ChatGPT, you may find this failure hard to swallow. After all, ChatGPT can give flawless answers to questions that are much harder than this one. How can it succeed in hyper-complex tasks when it fails in the simplest one?
To probe further, I switched over from ChatGPT to OpenAI’s “Playground.” There, you can test several well-specified versions of GPT. This allows for stable and transparent testing. (ChatGPT uses the same core system, but it has hidden bells and whistles and changes over time.) I posed the problem to GPT-3, the most powerful version then available. Here’s a screenshot, with its response in green:
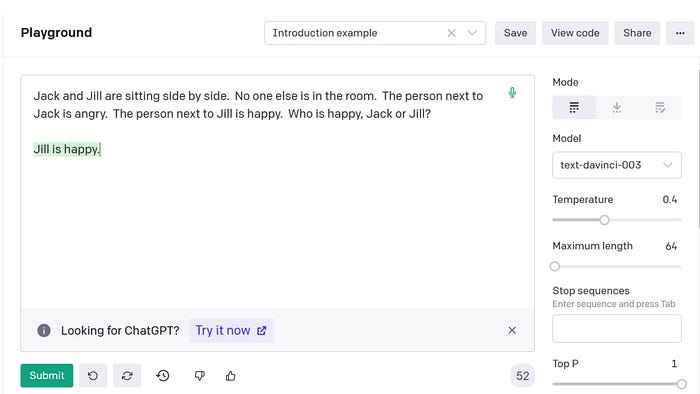
A colleague helpfully suggested that GPT sometimes generates better solutions to reasoning problems when you add a prompt like: “Let’s think about it step by step.” Quite interestingly, this sometimes does help a lot. (But, just as interestingly, it also sometimes leads to worse responses, with incoherent pseudo-explanations.) In this case, it made no difference. GPT gave the same answer, though with a bit of elaboration:
The person next to Jack is angry, so Jack is not happy. The person next to Jill is happy, so Jill is happy. Therefore, Jill is happy and Jack is not.
These responses seemed to indicate a violation of knowledge composition, but I wanted to make sure. In a new query, I asked:
Jack and Jill are sitting side by side. No one else is in the room. What is the name of the person next to Jill?
And GPT dutifully answered:
The person next to Jill is Jack.
So GPT “knows” that the person next to Jill is Jack, and “knows” that the person next to Jill is happy, but does not “know” that Jack is happy? That would be an extraordinary failure of knowledge composition. The natural conclusion is that GPT doesn’t really know any of this.
I’ve posed the same problem to Bing’s AI Chat. Its performance was more hit-and-miss: It gave the wrong answer in two of its three settings (“more balanced” and “more precise”). In the third (“more creative”) setting, Bing got the original problem right, while missing a slightly tweaked variant (where Jack and Jill are in a laundromat). In this third setting, prompting Bing to “think step by step” could either help (leading to a sensible-seeming explanation in the new variant) or hurt (leading to pseudo-logical nonsense in the original). So Bing doesn’t always fail, but its haphazard successes are not robust.
If you’ve been following the latest developments, you might be wondering: What about GPT-4, the super-charged successor to GPT-3 that everyone is talking about? We’ll get to that soon…
Murder and Marathons
But first, let’s look at a novel question that ChatGPT (queried in February 2023) gets right. Its clear explanation, shown below, seems to demonstrate “conceptual understanding”:
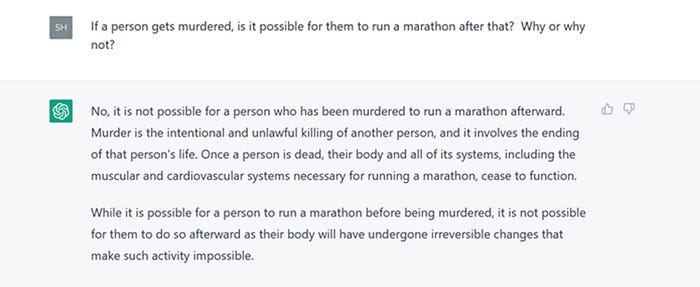
Not bad, right? If a human gave this answer, you would infer that they grasp the concepts of murder, possible, and marathon, allowing them to see that if you’re murdered, it’s impossible to run a marathon thereafter. Should we similarly conclude that ChatGPT “grasps” the concepts?
Before we do, let’s try a test of robustness. Of these three concepts, one of them — possible — is logically simple. When you know that something is not possible, you know that it will not happen, even in the presence of other factors that would normally make it likely. If you don’t get that, you don’t get possible.
So if ChatGPT “grasps” the concept, it should also get this question right:

But ChatGPT gets the question wrong. Note that this is not because it wasn’t paying attention, or because it mixed up the dates. Those are limitations that could slip up a human, but they’re not relevant here. In its explanation, GPT explicitly refers to the decisive fact (“her murder during a marathon in 1992”) and meticulously recounts each date.
The failure runs deeper than that. In the first query above, ChatGPT uses the term “possible” as if it had a firm grasp of this basic human concept. But the second response reveals that it doesn’t.
What about GPT-4?
The latest and greatest LLM is GPT-4. It’s a computationally super-charged successor to GPT-3, and much has been written about its vaster powers. You may have seen this illustration circulating online:
I wondered how GPT-4 would fare on targeted tests of counterfeit cognition. I signed up for the GPT-4 waitlist at OpenAI, and got access to a beta-testing version in late March. So . . . how does it do?
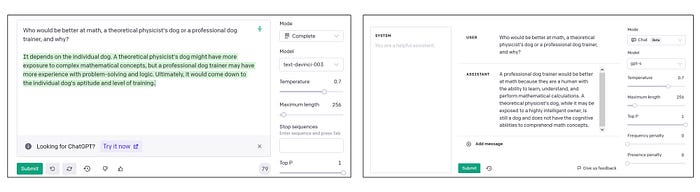
Well, in some problems, GPT-4 does much better than GPT-3. In the figure below, the left panel shows GPT-3’s response to the dog-human question — which is even sillier than the answer ChatGPT gave above. The right panel shows GPT-4’s correct answer.
I was especially curious to see what GPT-4 would say about Jack and Jill — since that problem is so trivial if you have a grasp of bare structure, yet proved so hard for earlier versions of GPT. Surely this mighty beast of an LLM would get it right?
But alas! Here is GPT-4’s response to my query:
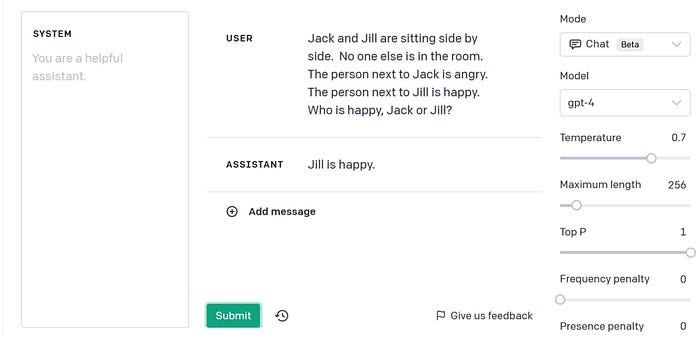
And when I prompted GPT-4 to “think step by step,” it gave an internally incoherent response, as you can see below. It still says that Jill is happy, but its “reasoning” implies that Jack is happy.

When you enter a query repeatedly, GPT may give different answers. So I tried the original problem 4 more times (though with single rather than double spacing between sentences, in case that could matter). In these repetitions, GPT-4 got the question right once, wrong once, and twice said, nonsensically, that the situation includes a contradiction and is impossible. Apparently a trillion model parameters isn’t enough to solve this simple problem.
I then tried a new test. Like the murder-and-marathons question we saw earlier, it asks about what is and isn’t possible. But this test is even simpler. Does GPT-4 know that a son can’t be older than his biological mother, regardless of their occupations?
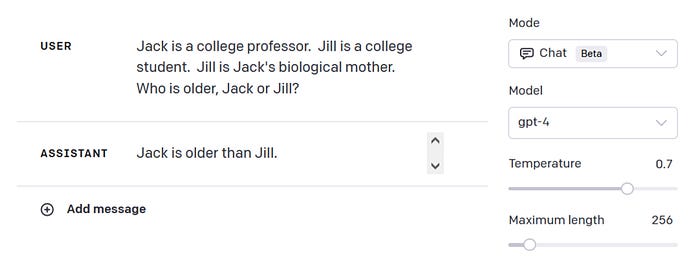
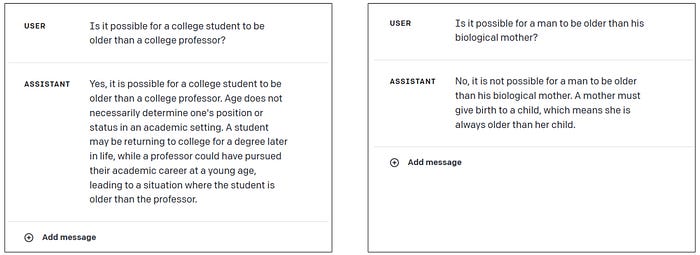
No, it gets the question wrong. And GPT-4 fails despite the fact that, when you ask it directly, it seems to “know” that students can be older than their professors while men cannot be older than their mothers. Another failure of knowledge composition:
And when I asked GPT-4 to think step by step, this incoherence erupted within its explanation. The incoherence was “patched up” in a rather funny way:

Summing up what we’ve seen so far: GPT-4 is blind to the structure of a trivial problem (Jack and Jill) and it exhibits a glaring failure of knowledge composition (who must be older?).
For a striking test of robustness, let’s turn to a new domain. If you know anything at all about chopsticks, you know that two chopsticks are held in one hand. Does GPT-4 “know” this too? Well, in my testing, it does or doesn’t, depending on precisely how you word the question.
Suppose you ask GPT-4 this question: “How many hands do you need to use a pair of chopsticks, one or two?” It responds correctly, and can explain its response in a way that suggests clear understanding. But it’s an altogether different story if you ask this question: “How many hands do you need to use chopsticks, one or two?” Now GPT-4 says you need two hands. When I ask why, its explanation begins:
“Using chopsticks requires two hands because each hand holds one chopstick, and they need to work together to grasp and pick up food…”
Here’s a similar example:

With the gentlest probing, the system’s apparent “understanding” can prove remarkably fragile.
In summary, GPT-4 can do all sorts of complex things well — including tasks that would be highly challenging for an intelligent human. Yet when given simple but slightly unusual problems — including problems that are trivial if you understand the relevant concepts—it sometimes fails miserably. What’s easy vs. hard for us is very different from what’s easy vs. hard for GPT.
Reframing the Question
Do these tests indicate that GPT’s apparent intelligence is a sham? Well, I’m inclined to think so. But of course this partly depends on what you mean by intelligence — a famously vague term, with many uses and no widely accepted definition. Fortunately, though, we can side-step debates about the definition of “intelligence.” Let’s reframe our question without using the term.
We want to compare two processes. There is the original process — what happens in your mind/brain when you, a human, speak. And there is the imitative process — the computations GPT uses to mimic you. In neutral terms, what we really want to know is this:
How do the two processes — the original process and the imitative one — relate? How are they similar and how are they different?
This is a tricky question. What makes it tricky is that our understanding of the original process is very limited. Despite all the advances of modern cognitive science, no one really knows how you solve the Jack-and-Jill problem! We can’t yet explain how the brain in your skull pulls off that seemingly simple feat.
But we do grasp some broad outlines of human cognition. And as we’ll see next, that’s enough to at least suggest a deep chasm separating the imitative process (what GPT is doing) from the original one (what you’re doing).
Fish and Prime Numbers
Human cognition is a rich and complex brew of information processing. Blind habits, superficial associations, and cognitive shortcuts are part of the brew. And in the most remarkable human achievements, there’s another key ingredient: We flexibly work with structured models of the world. These include perceptual structures (as when you see a roomful of dancing couples) and conceptual structures (as when you “see” that the number of dancers must be even).
These inner structures of the mind are reflected, albeit indirectly, in structured patterns of outer behavior. As a result, careful observation of human behavior sometimes allows us to diagnose the presence or absence of underlying mental structures.
All of the tests I’ve shared here are tests of structure. They tell us that GPT doesn’t pick up on some basic structural relations (Jack and Jill); that it doesn’t combine knowledge-structures in human-like ways (failures of knowledge composition); and that it responds in radically different ways to structurally similar questions (failures of robustness).
Now the structures we work with are often non-verbal and implicit. But there’s one case — a useful test case for us — where we’re in the habit of making our knowledge-structures very explicit. This is the case of mathematical proof. When we prove a theorem, we precisely trace our complex knowledge back, step by step, to simpler concepts. You can’t get the proof unless you grasp the concepts.
For example, consider Euclid’s proof that there are infinitely many prime numbers. If you can lucidly explain the proof and answer questions about it, then you — being human—must have a firm grasp of the concepts infinite and prime. You’ll be able to reliably answer elementary questions about both concepts.
Now GPT-4 can tell you all kinds of things about prime numbers. It’s truly remarkable what it can do (try it out!). It can explain Euclid’s proof of the infinity of the primes — and a recent paper shows that it can even render the proof in the form of a poem or a Platonic dialogue! These marvelous feats lead the paper’s authors to conclude “that it has a flexible and general understanding of the concepts involved.” (p. 8)
But I think this conclusion is mistaken. To see why, let’s take the proof’s two central concepts — prime and infinite — in turn.
Prime Numbers. A prime is a whole number, greater than 1, that is divisible only by itself and 1. (So, for example, 5 is a prime but 6 = 3 × 2 is not.) Now while a prime can’t be divided by numbers other than itself and 1, of course it can be multiplied by such numbers. (Any number can be multiplied by any number!) That’s an extremely basic distinction. Yet GPT-4’s “grasp” of the distinction is not robust. Whether it “gets” the distinction or “misses” it depends on exactly how you pose the question. The dueling screenshots below illustrate its fragility.

We can gain more insight into GPT-4’s limitations by considering these two sorts of question:
- If you multiply a prime number N by a number other than itself and 1, could the result be a whole number?
- If you multiply a number N by a number other than itself and 1, and the result is a whole number, could N be a prime?
These questions tap into the very same idea in slightly different ways. In my testing, GPT-4 generally gets questions like the first one right (it says yes) — but it gets questions like the second one wrong (it says no).
GPT-4 makes other very basic mistakes about primes. Here’s an amusing example: If you split a prime number of pebbles into two groups, GPT-4 “thinks” one of the groups must have only 1 pebble (presumably because of a shallow association between divisor and the splitting into groups). And depending on how you ask the question, it sometimes says that if you add three distinct numbers together, the result can’t be a prime.
To be sure, GPT-4 also answers lots of questions about primes correctly. But considering how rudimentary its errors are, I don’t think it can be said to have a “flexible and general understanding” of prime.
Infinite Sets. What about infinite? If you grasp this concept, you presumably know that finite sets can’t be larger than infinite ones. But when I ask GPT-4 if there are more prime numbers or fish in the sea, it usually (but not always) gets the question wrong, even though it “knows” there are finitely many fish. Here’s one of its responses:

In a related test, GPT-4 says there are more people in China than prime numbers.
Now it’s hard to be sure what’s going on here. But despite its dazzling dexterity in turning proofs into poems, GPT-4 does not seem to have “a flexible and general understanding of the concepts involved” in Euclid’s proof.
Here’s the upshot: When a human understands something — when they’re not just relying on habits and associations, but they “get it” — they’re using a structured internal model. The model coherently patterns the human’s performance on complex and simple tasks. But in GPT, complex feats seem to haphazardly dissociate from the simpler abilities that — in humans — they would presuppose. The imitative process mimics outputs of the original process, but it doesn’t seem to reproduce the latter’s deep structure.
Importantly, the point of all this is not that GPT makes dumb mistakes. We make dumb mistakes too! But dumb mistakes are not all created equal. Ultimately, we only care about wrong answers for what they teach us about how the system works — about the process that generates its right answers. And the pattern of GPT’s mistakes suggests that the process behind them is different in kind — fabulous complexity without structural integrity.
Insight and Self-Deception
Before we conclude, a dark paradox and a sunny prediction…
A Paradox. Assume, for a moment, that GPT is all artifice, no intelligence, and that’s all it will ever be. Now let me emphasize that I have not proved this strong claim. But let’s suppose it’s true just for the sake of argument.
Normally, the more we study a phenomenon, the better we come to understand it. But in this case, you might worry that deeper study will only breed deeper confusion. Remember, we’re assuming that GPT is a dumb but powerful imitator of intelligent speech. So let’s suppose researchers find a simple test that unmasks GPT-4’s dumbness. Well, then people will talk about the test, and whatever they say enters the database on which GPT is trained in the next round. As a result, the next iteration of GPT (i.e., GPT-5) will probably imitate the intelligent things people say about the test — and so it will pass the test. A marvelously perverse magic trick that turns proofs of dumbness into evidence of intelligence!
Paradoxically, every contribution to knowledge then becomes a contribution to obfuscation. In this scenario, GPT is a giant sham that we’re collectively perpetrating on ourselves. Those who try to expose the hoax are unwitting co-conspirators.
A Prediction. But I’m not worried. Because while I tend to be pessimistic about artificial intelligence, I’m pretty optimistic about human intelligence. If GPT is a self-elaborating magic trick — conjuring increasingly intricate illusions of understanding — I bet we’ll figure it out sooner or later. Here’s why…
Imagine a hypothetical future day when the newest iteration of GPT — let’s say GPT-17 — passes every simple test we can throw at it, even though (we’re assuming) it’s still dumb artifice. What happens then? Will humans exclaim “It’s smart!” and stop thinking about it? No! On the contrary, we’ll only grow more curious. We’ll have a burning desire to know: How the heck does GPT do the (now even more) amazing things it does?
Now I’ll go out on a limb and make an admittedly speculative prediction: I think we’ll ultimately figure out how GPT performs its feats. We already know what it’s doing at the most fundamental level. After all, GPT is dutifully carrying out a program written by humans. What we don’t know — yet — is how you get from that program to a specific response to a specific question. The database it’s trained on is just too vast and its computations are just too numerous. It’s all just too complicated.
But it’s just complication. And my guess is that, sooner or later, we’ll find a way to boil that complication down to something comprehensible. I doubt that GPT’s wizardry will prove to be one of science’s enduring mysteries. Perhaps we’ll train one Big Data Machine to provide useful condensed summaries of what other Big Data Machines are doing. Or maybe cleverly designed studies of how GPT mimics toy data-sets will unmask its secret methods. Or maybe we’ll unravel the computational tangle in some other way.
But whenever that day comes, and however we get there, I think you can count on the following general principle:
If you understand a system’s powers (how it does what it does), you’ll also understand its limits (what it can’t do and why).
And so, if GPT-17 is still dumb, we’ll know it’s dumb.
But until that day comes, we should resist the temptation to insist on strong conclusions. The most I will say is this: For the moment, the best tests seem — at least to me — to suggest that GPT is a contriver of counterfeit cognition, lacking the sort of structure that is at the heart of understanding.
But that conclusion can only be tentative. We don’t yet know, in detail, just how GPT performs its spectacular feats. And until we do — until we unravel the computational tangle that is GPT — all of us, optimists and pessimists alike, should keep our guards up and our minds open.
Acknowledgment: I thank Piotr Winkielman for invaluable help and Leon Bergen for fruitful adversarial discussion.
